

Cara Memasang dan Konfigurasi Hive Dengan Ketersediaan Tinggi - Bahagian 7

- 4579
- 1125
- Ronnie Hermann
Sarang ialah Gudang Data model dalam Hadoop Sistem Eco. Ia boleh dilakukan sebagai alat ETL di atas Hadoop. Membolehkan ketersediaan tinggi (HA) di sarang tidak serupa seperti yang kita lakukan dalam perkhidmatan induk seperti Namenode dan Pengurus Sumber.
Failover automatik tidak akan berlaku di Sarang (Hiveserver2). Jika ada Hiveserver2 (HS2) gagal, menjalankan pekerjaan pada yang gagal HS2 akan gagal. Kita perlu menyerahkan semula pekerjaan itu supaya pekerjaan dapat berjalan di lain -lain Hiveserver2. Jadi, membolehkan Ha pada HS2 tidak lain tetapi meningkatkan jumlah HS2 komponen dalam Kelompok.
Dalam artikel ini, kita akan melihat langkah -langkah untuk memasang dan membolehkan Ketersediaan tinggi dari Sarang.
Keperluan
- Amalan Terbaik untuk Menggunakan Hadoop Server di CentOS/RHEL 7 - Bahagian 1
- Menyediakan prasyarat Hadoop dan pengerasan keselamatan - Bahagian 2
- Cara Memasang dan Mengkonfigurasi Pengurus Cloudera di CentOS/RHEL 7 - Bahagian 3
- Cara Memasang CDH dan Konfigurasikan Penempatan Perkhidmatan di CentOS/RHEL 7 - Bahagian 4
- Cara Menyediakan Ketersediaan Tinggi Untuk Namenode - Bahagian 5
- Cara Menyediakan Ketersediaan Tinggi Untuk Pengurus Sumber - Bahagian 6
Mari kita mulakan…
Pemasangan dan konfigurasi sarang
1. Log masuk ke Pengurus Cloudera di URL di bawah dan menavigasi ke Pengurus Cloudera -> Tambah perkhidmatan.
http: // 13.233.129.39: 7180/cmf/rumah
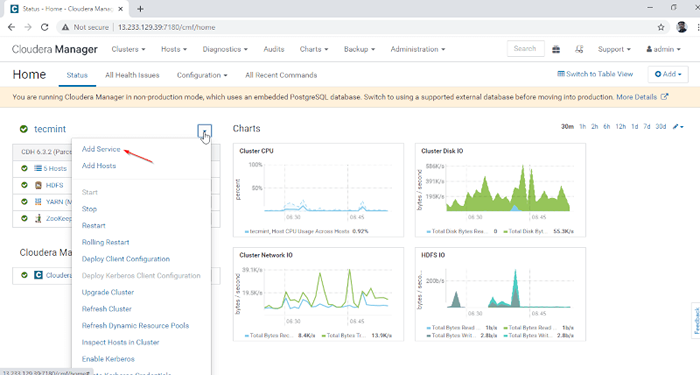 Tambahkan Perkhidmatan dalam Pengurus Cloudera
Tambahkan Perkhidmatan dalam Pengurus Cloudera 2. Pilih perkhidmatan 'Sarang'.
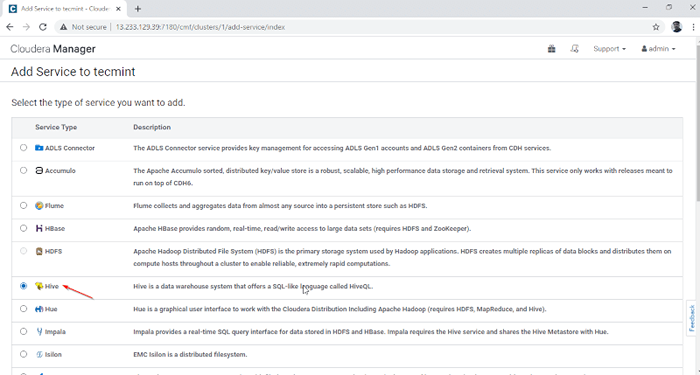 Pilih Perkhidmatan Hive
Pilih Perkhidmatan Hive 3. Berikan perkhidmatan pada nod.
- Gateway - Ia adalah perkhidmatan pelanggan di mana pengguna dapat mengakses sarang. Biasanya, perkhidmatan ini akan diletakkan Hujung nod yang didedikasikan kepada pengguna.
- Hive Metastore - Ia adalah repositori pusat untuk menyimpan metadata sarang.
- Pelayan webhcat - Ia adalah API web untuk hcatalog dan perkhidmatan hadoop lain.
- Hiveserver2 - Ini adalah antara muka pelanggan untuk pelaksanaan pertanyaan di sarang.
Setelah memilih pelayan, klik 'Teruskan'Untuk meneruskan.
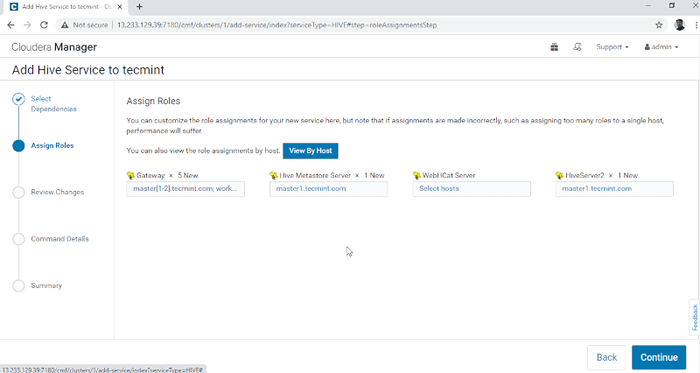 Memberikan perkhidmatan sebagai nod
Memberikan perkhidmatan sebagai nod 4. Hive Metastore memerlukan pangkalan data asas untuk menyimpan metadata. Di sini kita menggunakan lalai PostgreSQL pangkalan data yang dibina dengan Cdh.
Butiran pangkalan data yang disebutkan di bawah akan dimasukkan secara automatik, 'Sambungan ujian'akan dilangkau kerana pangkalan data yang disebutkan akan dibuat dengan cepat. Dalam masa nyata, kita perlu membuat pangkalan data dalam pangkalan data luaran dan menguji sambungan untuk meneruskan lebih lanjut. Setelah selesai, sila klik 'Teruskan'.
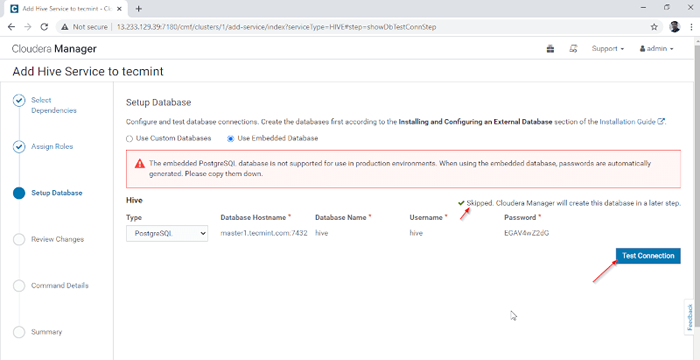 Pangkalan data persediaan
Pangkalan data persediaan 5. Konfigurasikan Hive Warehouse direktori, /pengguna/sarang/gudang adalah laluan direktori lalai untuk menyimpan jadual sarang. Klik 'Teruskan'.
 Pilih Direktori Gudang Hive
Pilih Direktori Gudang Hive 6. Pemasangan Hive dimulakan.
 Kemajuan pemasangan sarang
Kemajuan pemasangan sarang 7. Setelah pemasangan selesai, anda boleh mendapatkan 'Selesai'Status. Klik 'Teruskan'Untuk meneruskan lebih jauh.
 Pemasangan sarang selesai
Pemasangan sarang selesai 8. Pemasangan dan konfigurasi sarang berjaya diselesaikan. Klik 'Selesai'Untuk menyelesaikan prosedur pemasangan.
 Selesaikan pemasangan sarang
Selesaikan pemasangan sarang 9. Anda dapat melihat Sarang perkhidmatan ditambah dalam Kelompok melalui Dashboard Pengurus Cloudera.
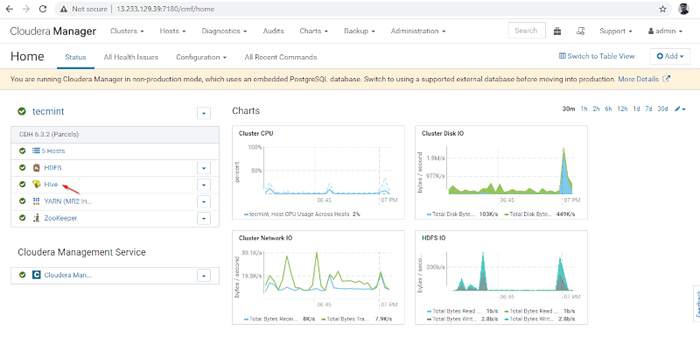 Perkhidmatan Hive ditambah
Perkhidmatan Hive ditambah 10. Anda boleh melihat Hiveserver2 dalam Contoh dari Sarang. Kami telah menambah Hiveserver2 dalam Master1.
Pengurus Cloudera -> Sarang -> Contoh -> Hiveserver2.
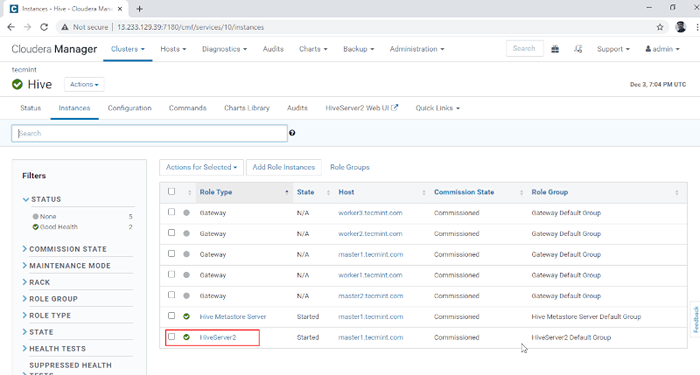 Lihat contoh Hiveserver2
Lihat contoh Hiveserver2 Membolehkan ketersediaan tinggi di sarang
11. Seterusnya menambah peranan sarang dengan pergi Pengurus Cloudera -> Sarang -> Tindakan -> Tambah peranan Contoh.
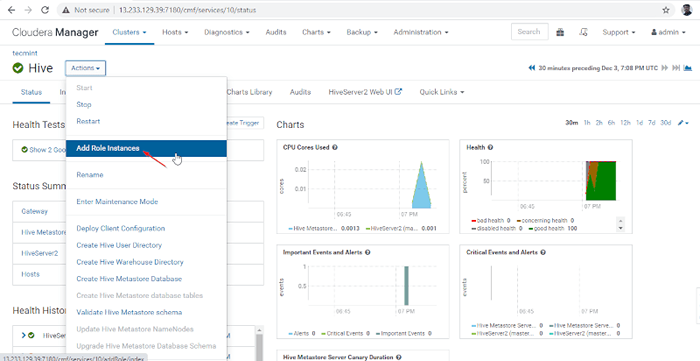 Tambahkan contoh peranan sarang
Tambahkan contoh peranan sarang 12. Pilih pelayan di mana anda ingin meletakkan tambahan Hiveserver2. Anda boleh menambah lebih daripada dua, tidak ada had. Di sini kami menambah tambahan Hiveserver2 dalam Master2.
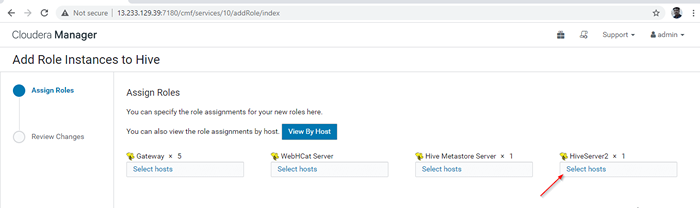 Pilih Pelayan untuk Hive
Pilih Pelayan untuk Hive 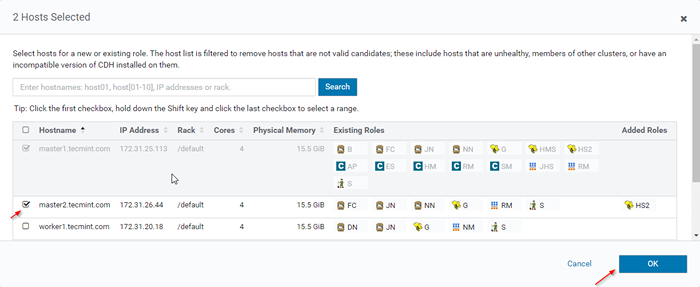 Pilih pelayan tuan rumah
Pilih pelayan tuan rumah 13. Setelah memilih pelayan, klik 'Teruskan'.
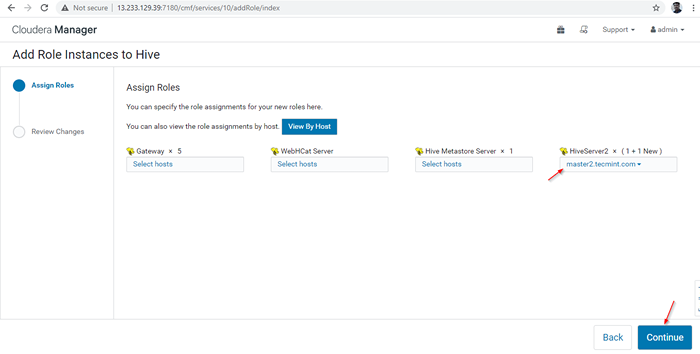 Pelayan ditambahkan
Pelayan ditambahkan 14. A Hiverserver2 akan dimasukkan ke dalam Contoh sarang, anda perlu memulakannya dengan pergi Pengurus Cloudera -> Sarang -> Contoh -> (Pilih Hiveserver2 ditambah baru) -> Tindakan untuk dipilih -> Mula.
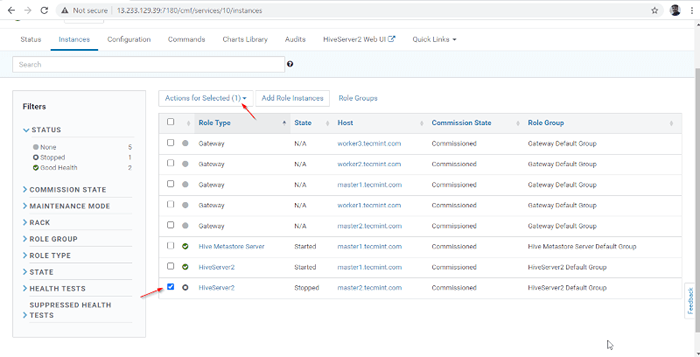 Pilih pelayan sarang
Pilih pelayan sarang 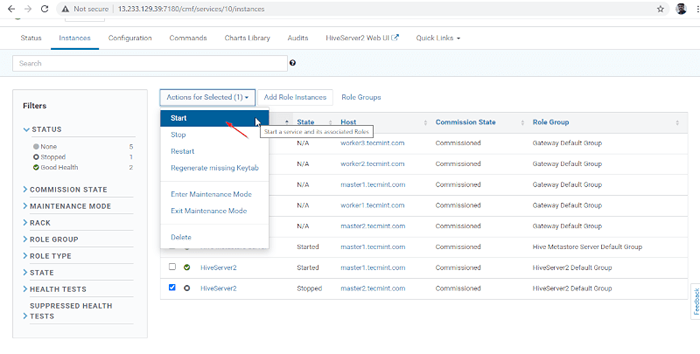 Mulakan pelayan sarang
Mulakan pelayan sarang 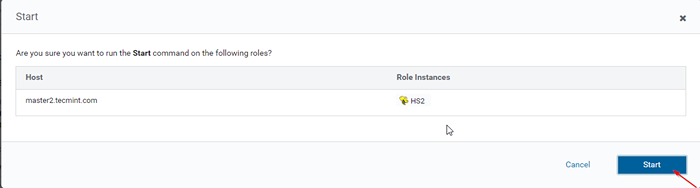 Mulakan pelayan sarang
Mulakan pelayan sarang 15. Sekali Hiveserver2 Bermula Master2, anda akan mendapat status 'Selesai'. Klik Tutup.
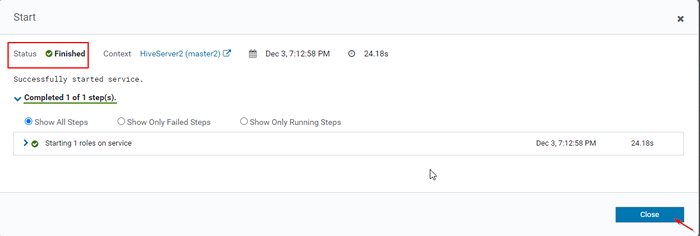 Status selesai
Status selesai 16. Anda boleh melihat, kedua -duanya Hiveserver2s sedang berjalan.
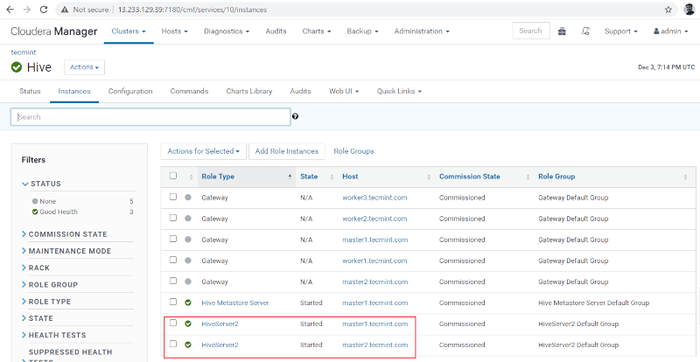 Sahkan status pelayan sarang
Sahkan status pelayan sarang Mengesahkan ketersediaan sarang
Kita boleh menyambungkan Hiveserver2 melalui beeline yang merupakan pelanggan nipis dan baris arahan. Ia menggunakan pemandu JDBC untuk menubuhkan sambungan.
17. Log masuk ke pelayan di mana Hive Gateway adalah berlari.
[[dilindungi e -mel] ~] $ beeline
 Sambung ke Hiveserver2
Sambung ke Hiveserver2 18. Masuk ke JDBC rentetan sambungan untuk menyambung Hiveserver2. Dalam hubungan ini, tali Kami menyebutkan Hiverserver2 (Master2) dengan nombor port lalainya 10000. Rentetan sambungan ini hanya akan menyambung ke Hiveserver2 yang sedang berjalan Master2.
beeline> !Sambung "JDBC: Hive2: // Master1.Tecmint.com: 10000 "
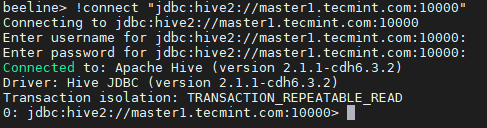 String sambungan JDBC
String sambungan JDBC 19. Jalankan pertanyaan contoh.
0: JDBC: Hive2: // Master1.Tecmint.com: 10000> menunjukkan pangkalan data;
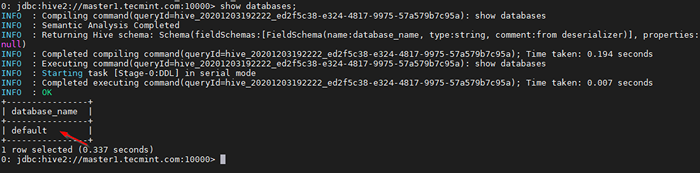 Jalankan pertanyaan sampel
Jalankan pertanyaan sampel Ini adalah pangkalan data lalai yang dibina.
20. Gunakan arahan di bawah untuk menamatkan sesi sarang.
0: JDBC: Hive2: // Master1.Tecmint.com: 10000> !berhenti
 Berhenti sesi sarang
Berhenti sesi sarang 21. Anda boleh menggunakan cara yang sama untuk disambungkan Hiveserver2 Berlari Master2.
beeline> !Sambung "JDBC: Hive2: // Master2.Tecmint.com: 10000 "
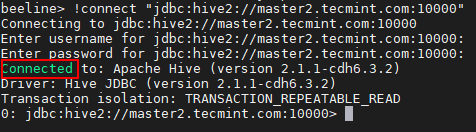 Sambungkan ke pelayan sarang
Sambungkan ke pelayan sarang 23. Kita boleh menyambungkan Hiveserver2 dalam Penemuan Zookeeper mod. Dalam kaedah ini, kita tidak perlu menyebutnya Hiveserver2 dalam rentetan sambungan sebaliknya kita menggunakan Penjaga zoo Untuk mengetahui yang ada Hiveserver2.
Di sini kita boleh menggunakan pengimbang beban pihak ketiga untuk mengimbangi beban di antara yang ada Hiverserver2. Konfigurasi di bawah adalah perlu membolehkan Mod Penemuan Zookeeper dengan pergi ke Pengurus Cloudera -> Sarang -> Konfigurasi.
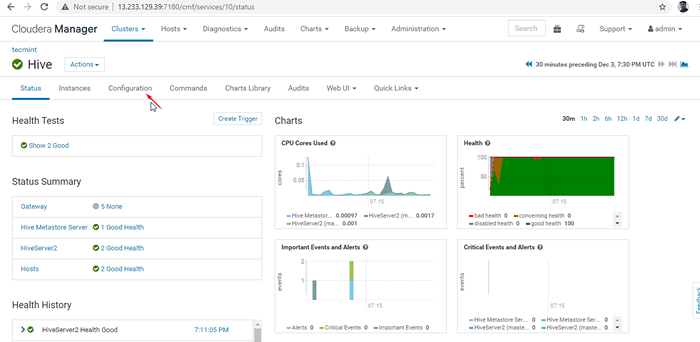 Dayakan mod penemuan zookeeper
Dayakan mod penemuan zookeeper 24. Seterusnya, cari harta itu "Coretan Konfigurasi Lanjutan Hiveserver2"Dan klik + simbol untuk menambah harta di bawah.
Nama: sarang.Server2.sokongan.dinamik.perkhidmatan.Nilai Penemuan: Penerangan Benar:
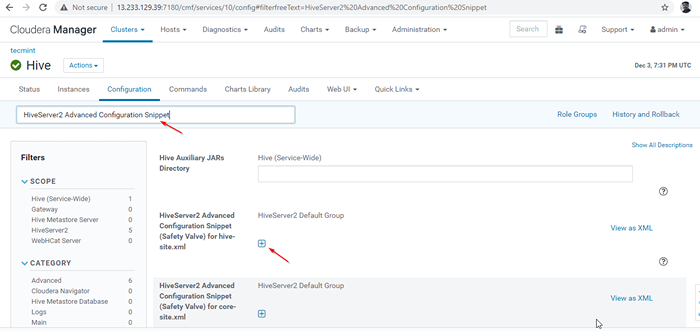 Coretan Konfigurasi Lanjutan Hiveserver2
Coretan Konfigurasi Lanjutan Hiveserver2 25. Setelah memasuki harta benda, klik 'Simpan perubahan'.
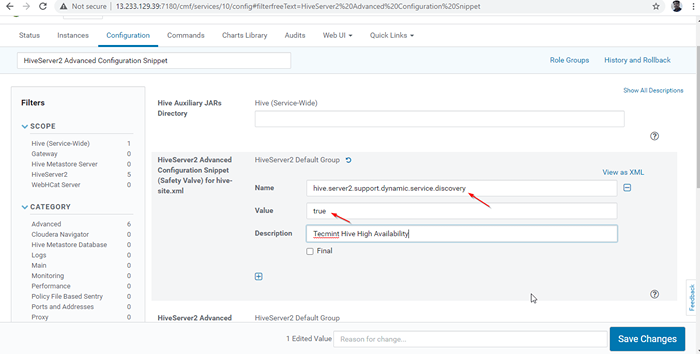 Tambah harta
Tambah harta 26. Semasa kami membuat perubahan kepada konfigurasi, perlu memulakan semula perkhidmatan yang terjejas dengan mengklik simbol warna oren untuk memulakan semula perkhidmatan.
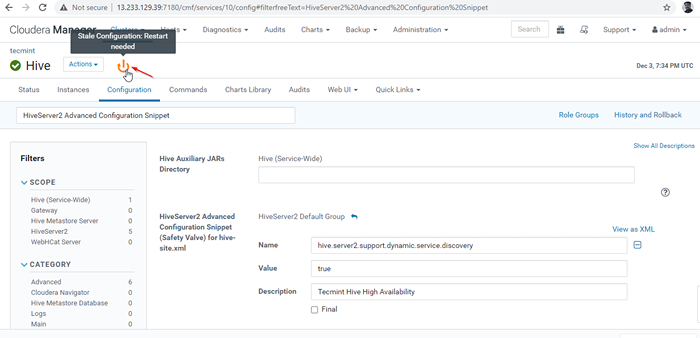 Memulakan semula perkhidmatan
Memulakan semula perkhidmatan 27. Klik 'Mulakan semula basi'Perkhidmatan.
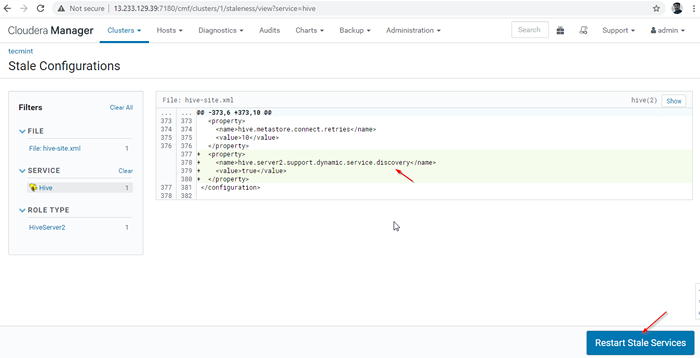 Mulakan semula perkhidmatan basi
Mulakan semula perkhidmatan basi 28. Terdapat dua pilihan yang ada. Sekiranya kelompok dalam pengeluaran secara langsung, kita perlu lebih suka memulakan semula untuk meminimumkan gangguan. Seperti yang kita baru memasang, kita boleh memilih pilihan kedua 'Menggunakan semula konfigurasi pelanggan', dan klik'Mulakan semula sekarang'.
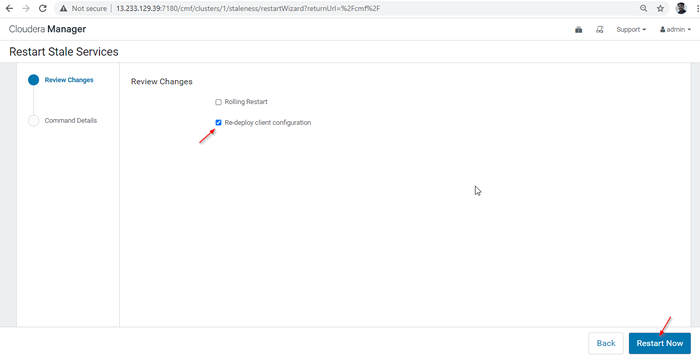 Menggunakan semula konfigurasi pelanggan
Menggunakan semula konfigurasi pelanggan 29. Setelah mulakan semula selesai, anda akan mendapat status 'Selesai'. Klik 'Selesai'Untuk menyelesaikan proses.
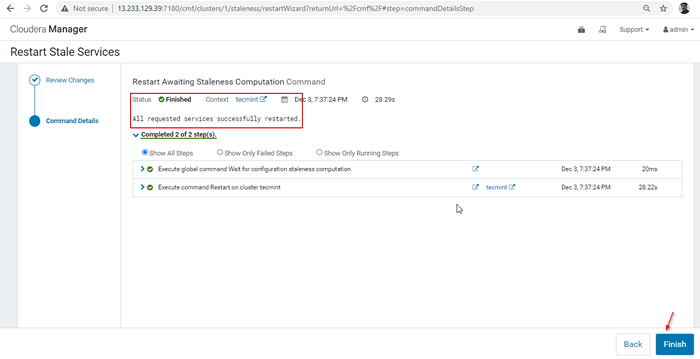 Menyelesaikan proses
Menyelesaikan proses 30. Sekarang kita akan menghubungkan Hiveserver2 menggunakan Penemuan Zookeeper mod. Di dalam JDBC sambungan, rentetan yang kita perlukan untuk menggunakan Penjaga zoo pelayan dengan nombor portnya 2081. Kumpulkan pelayan Zookeeper dengan pergi ke Pengurus Cloudera -> Penjaga zoo -> Contoh -> (Perhatikan nama pelayan).
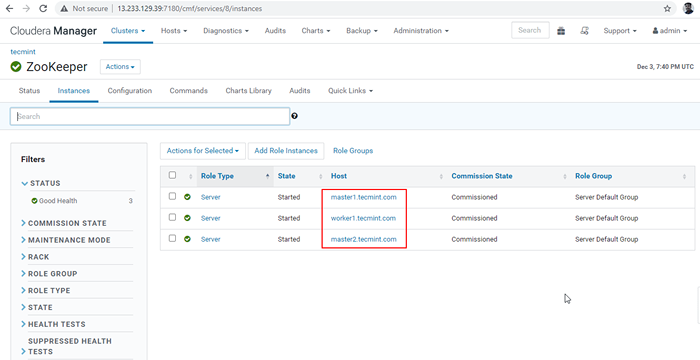 Pelayan zookeeper
Pelayan zookeeper Ini adalah tiga pelayan yang mempunyai zookeeper, 2181 adalah nombor port.
Master1.Tecmint.com: 2181 Master2.Tecmint.com: 2181 pekerja1.Tecmint.com: 2181
31. Sekarang masuk Beeline.
[[dilindungi e -mel] ~] $ beeline
 Sambung ke Beeline
Sambung ke Beeline 32. Masuk ke JDBC rentetan sambungan seperti yang disebutkan di bawah. Kita mesti menyebutnya Mod Penemuan Perkhidmatan dan Ruang nama Zookeeper. 'Hiveserver2'adalah ruang nama lalai Hiveserver2.
beeline>!Sambung "JDBC: Hive2: // Master1.Tecmint.com: 2181, master2.Tecmint.com: 2181, pekerja1.Tecmint.com: 2181/; ServiceDiscoveryMode = Zookeeper; ZookeeperNamesPace = Hiveserver2 "
 Masukkan rentetan sambungan jdbc
Masukkan rentetan sambungan jdbc 33. Sekarang sesi disambungkan ke Hiveserver2 Berlari Master1. Jalankan pertanyaan sampel untuk mengesahkan. Gunakan arahan di bawah untuk membuat pangkalan data.
0: JDBC: Hive2: // Master1.Tecmint.com: 2181, MAST> Buat pangkalan data Tecmint;
 Buat pangkalan data
Buat pangkalan data 34. Gunakan arahan di bawah untuk menyenaraikan pangkalan data.
0: JDBC: Hive2: // Master1.Tecmint.com: 2181, tiang> menunjukkan pangkalan data;
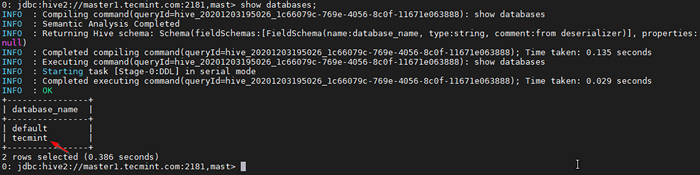 Senarai pangkalan data
Senarai pangkalan data 35. Sekarang kita akan mengesahkan ketersediaan tinggi di Mod Penemuan Zookeeper. Pergi ke Pengurus Cloudera dan hentikan Hiveserver2 pada Master1 bahawa kami telah diuji di atas.
Pengurus Cloudera -> Sarang -> Contoh -> (pilih Hiveserver2 pada Master1) -> Tindakan untuk dipilih -> Berhenti.
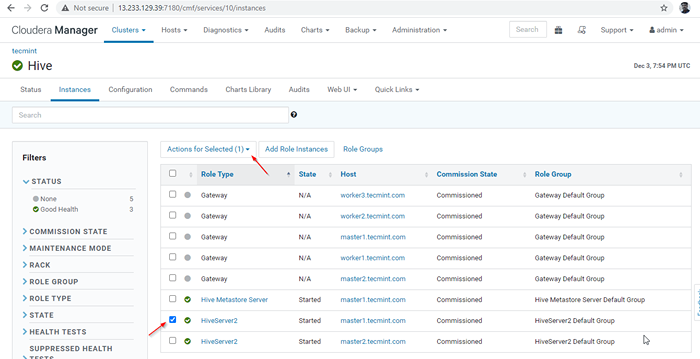 Pilih pelayan sarang
Pilih pelayan sarang  Hentikan pelayan sarang
Hentikan pelayan sarang 36. Klik 'Berhenti'. Setelah berhenti, anda akan mendapat status 'Selesai'. Sahkan Hiveserver2 pada Master1 dengan menavigasi ke Sarang -> Contoh.
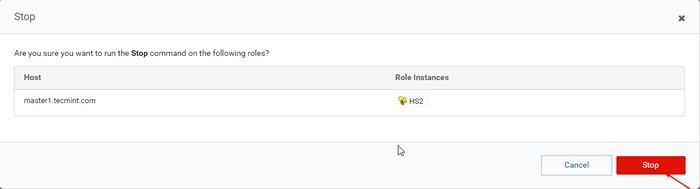 Hentikan pelayan sarang
Hentikan pelayan sarang 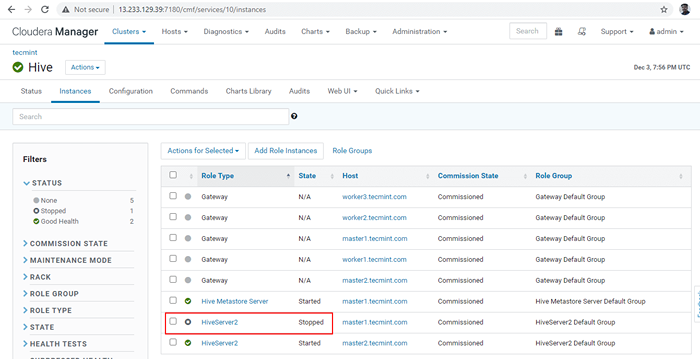 Sahkan pelayan sarang
Sahkan pelayan sarang 37. Masuk ke dalam Beeline dan sambungkan Hiveserver2 menggunakan yang sama JDBC rentetan sambungan dengan Mod Penemuan Zookeeper seperti yang kita lakukan dalam langkah -langkah di atas.
[[dilindungi e -mel] ~] $ beeline beeline>!Sambung "JDBC: Hive2: // Master1.Tecmint.com: 2181, master2.Tecmint.com: 2181, pekerja1.Tecmint.com: 2181/; ServiceDiscoveryMode = Zookeeper; ZookeeperNamesPace = Hiveserver2 "
 Sambungkan Hiveserver2
Sambungkan Hiveserver2 Sekarang anda akan dihubungkan dengan Hiveserver2 Berlari Master2.
38. Sahkan dengan pertanyaan sampel.
0: JDBC: Hive2: // Master1.Tecmint.com: 2181, tiang> menunjukkan pangkalan data;
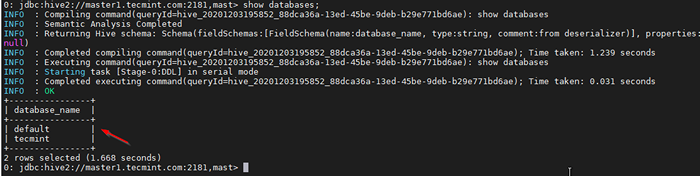 Mengesahkan pertanyaan sampel
Mengesahkan pertanyaan sampel Kesimpulan
Dalam artikel ini, kami telah melalui langkah -langkah terperinci untuk mempunyai Gudang data sarang Model dalam kami Kelompok dengan Ketersediaan tinggi. Dalam persekitaran pengeluaran masa nyata, lebih daripada tiga Hiveserver2 akan diletakkan dengan Mod Penemuan Zookeeper didayakan.
Di sini, semua Hiveserver2's sedang mendaftar dengan Penjaga zoo di bawah umum Ruang nama. Zookeeper secara dinamik mendapati yang ada Hiveserver2 dan menetapkan sesi sarang.
- « Cara Memasang Workstation VMware 16 Pro di Linux Systems
- Cara Memasang Kluster Kubernet di CentOS 8 »