

Ubuntu 20.04 Hadoop

- 3525
- 851
- Wendell Shields
Apache Hadoop terdiri daripada pelbagai pakej perisian sumber terbuka yang berfungsi bersama untuk penyimpanan yang diedarkan dan diedarkan pemprosesan data besar. Terdapat empat komponen utama untuk Hadoop:
- Hadoop biasa - Pelbagai Perpustakaan Perisian yang Hadoop bergantung kepada untuk dijalankan
- Hadoop diedarkan Sistem Fail (HDFS) - sistem fail yang membolehkan pengedaran dan penyimpanan data besar yang cekap merentasi kumpulan komputer
- Hadoop MapReduce - digunakan untuk memproses data
- Benang Hadoop - API yang menguruskan peruntukan sumber pengkomputeran untuk keseluruhan kelompok
Dalam tutorial ini, kami akan pergi ke langkah -langkah untuk memasang Hadoop versi 3 di Ubuntu 20.04. Ini akan melibatkan memasang HDFS (Namenode dan Datanode), benang, dan MapReduce pada kluster nod tunggal yang dikonfigurasi dalam mod diedarkan pseudo, yang diedarkan simulasi pada mesin tunggal. Setiap komponen Hadoop (HDFS, Benang, MapReduce) akan berjalan pada nod kami sebagai proses Java yang berasingan.
Dalam tutorial ini anda akan belajar:
- Cara Menambah Pengguna untuk Persekitaran Hadoop
- Cara Memasang Prasyarat Java
- Cara Mengkonfigurasi SSH Tanpa Kata Laluan
- Cara Memasang Hadoop dan Konfigurasi Fail XML Berkaitan yang Diperlukan
- Cara Memulakan Kluster Hadoop
- Cara Mengakses UI Web Namenode dan ResourceManager
Apache Hadoop di Ubuntu 20.04 Focal Fossa | Kategori | Keperluan, konvensyen atau versi perisian yang digunakan |
|---|---|
| Sistem | Dipasang Ubuntu 20.04 atau dinaik taraf Ubuntu 20.04 Focal Fossa |
| Perisian | Apache Hadoop, Java |
| Yang lain | Akses istimewa ke sistem linux anda sebagai akar atau melalui sudo perintah. |
| Konvensyen | # - Memerlukan arahan Linux yang diberikan untuk dilaksanakan dengan keistimewaan akar sama ada secara langsung sebagai pengguna root atau dengan menggunakan sudo perintah$ - Memerlukan arahan Linux yang diberikan sebagai pengguna yang tidak layak |
Buat Pengguna untuk Persekitaran Hadoop
Hadoop semestinya mempunyai akaun pengguna berdedikasi sendiri di sistem anda. Untuk mencipta satu, buka terminal dan taipkan arahan berikut. Anda juga akan diminta membuat kata laluan untuk akaun.
$ sudo adduser Hadoop
 Buat pengguna Hadoop baru
Buat pengguna Hadoop baru Pasang prasyarat Java
Hadoop didasarkan pada Java, jadi anda perlu memasangnya pada sistem anda sebelum dapat menggunakan Hadoop. Pada masa penulisan ini, versi Hadoop semasa 3.1.3 memerlukan Java 8, jadi itulah yang akan kami pasang di sistem kami.
Gunakan dua arahan berikut untuk mengambil senarai pakej terkini di Apt dan pasang Java 8:
$ sudo apt update $ sudo apt pemasangan openjdk-8-jdk openjdk-8-jre
Konfigurasikan ssh tanpa kata laluan
Hadoop bergantung kepada SSH untuk mengakses nodnya. Ia akan menyambung ke mesin terpencil melalui SSH serta mesin tempatan anda jika anda mempunyai Hadoop yang berjalan di atasnya. Jadi, walaupun kami hanya menubuhkan Hadoop di mesin tempatan kami dalam tutorial ini, kami masih perlu memasang SSH. Kami juga perlu mengkonfigurasi ssh tanpa kata laluan
Jadi Hadoop secara senyap boleh mewujudkan sambungan di latar belakang.
- Kami memerlukan kedua -dua Pakej Pelayan OpenSsh dan OpenSsh Client. Pasangnya dengan arahan ini:
$ sudo apt memasang openssh-server openssh-client
- Sebelum meneruskan, sebaiknya dilog masuk
HadoopAkaun Pengguna yang kami buat sebelum ini. Untuk menukar pengguna di terminal semasa anda, gunakan arahan berikut:$ Su Hadoop
- Dengan pakej tersebut, sudah tiba masanya untuk menjana pasangan utama awam dan swasta dengan arahan berikut. Perhatikan bahawa terminal akan mendorong anda beberapa kali, tetapi yang perlu anda lakukan adalah terus memukul
Masukkanuntuk meneruskan.$ ssh -keygen -t rsa
 Menjana kekunci RSA untuk ssh tanpa kata laluan
Menjana kekunci RSA untuk ssh tanpa kata laluan - Seterusnya, salin kunci RSA yang baru dijana
id_rsa.pubkediberi kuasa_keys:$ kucing ~/.SSH/ID_RSA.pub >> ~/.SSH/Authorized_keys
- Anda boleh memastikan bahawa konfigurasi itu berjaya dengan sshing ke localhost. Sekiranya anda dapat melakukannya tanpa diminta untuk kata laluan, anda boleh pergi.
 Sshing ke dalam sistem tanpa diminta untuk kata laluan bermaksud ia berfungsi
Sshing ke dalam sistem tanpa diminta untuk kata laluan bermaksud ia berfungsi
Pasang Hadoop dan konfigurasikan fail XML yang berkaitan
Pergi ke laman web Apache untuk memuat turun Hadoop. Anda juga boleh menggunakan arahan ini jika anda ingin memuat turun versi 3 Hadoop 3.1.3 binari secara langsung:
$ wget https: // muat turun.Apache.Org/Hadoop/Common/Hadoop-3.1.3/Hadoop-3.1.3.tar.Gz
Ekstrak muat turun ke Hadoop Direktori rumah pengguna dengan arahan ini:
$ tar -XZVF Hadoop -3.1.3.tar.gz -c /home /hadoop
Menyediakan pemboleh ubah persekitaran
Yang berikut eksport Perintah akan mengkonfigurasi pembolehubah persekitaran Hadoop yang diperlukan pada sistem kami. Anda boleh menyalin dan menampal semua ini ke terminal anda (anda mungkin perlu menukar baris 1 jika anda mempunyai versi Hadoop yang berbeza):
Eksport HADOOP_HOME =/rumah/Hadoop/Hadoop-3.1.3 eksport hadoop_install = $ Hadoop_Home Export Hadoop_Mapred_Home = $ Hadoop_Home Export Hadoop_Common_Home = $ Hadoop_Home Export Hadoop_Hdfs_Home = $ Hadoop_Home Export Yarn_Home Eksport Hadoop_Opts = "-Djava.Perpustakaan.Path = $ hadoop_home/lib/asli "Sumber .Bashrc Fail dalam sesi log masuk semasa:
$ sumber ~/.Bashrc
Seterusnya, kami akan membuat beberapa perubahan pada Hadoop-ENV.sh fail, yang boleh didapati di direktori pemasangan Hadoop di bawah /etc/Hadoop. Gunakan Nano atau editor teks kegemaran anda untuk membukanya:
$ nano ~/Hadoop-3.1.3/etc/Hadoop/Hadoop-ENV.sh
Tukar Java_home pemboleh ubah ke mana Java dipasang. Di sistem kami (dan mungkin juga milik anda, jika anda menjalankan Ubuntu 20.04 dan telah mengikuti bersama kami setakat ini), kami mengubah garis itu ke:
Eksport java_home =/usr/lib/jvm/java-8-opengdk-amd64
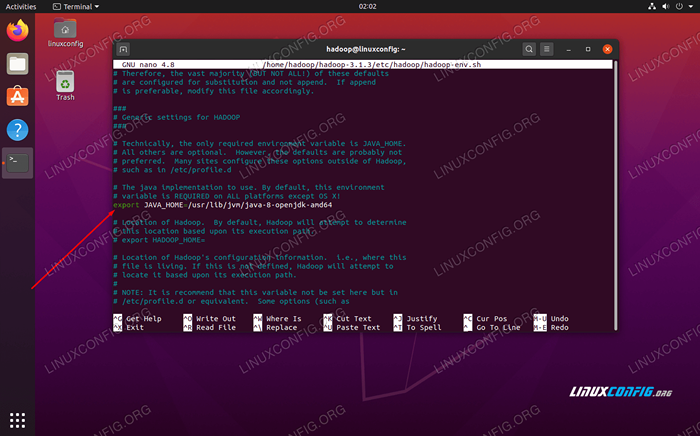 Tukar pembolehubah persekitaran java_home
Tukar pembolehubah persekitaran java_home Itu akan menjadi satu -satunya perubahan yang perlu kita buat di sini. Anda boleh menyimpan perubahan anda pada fail dan menutupnya.
Perubahan konfigurasi di tapak teras.Fail XML
Perubahan seterusnya yang perlu kita buat adalah di dalam tapak teras.XML fail. Buka dengan arahan ini:
$ nano ~/Hadoop-3.1.3/etc/Hadoop/Laman Teras.XML
Masukkan konfigurasi berikut, yang mengarahkan HDFS untuk dijalankan di port localhost 9000 dan menetapkan direktori untuk data sementara.
fs.defaultfs hdfs: // localhost: 9000 Hadoop.TMP.dir/rumah/hadoop/hadooptmpdata 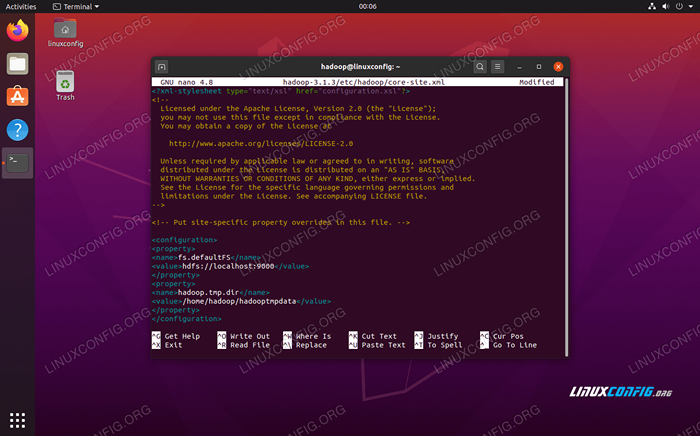 tapak teras.Perubahan fail konfigurasi XML
tapak teras.Perubahan fail konfigurasi XML Simpan perubahan anda dan tutup fail ini. Kemudian, buat direktori di mana data sementara akan disimpan:
$ mkdir ~/hadooptmpdata
Perubahan konfigurasi di tapak HDFS.Fail XML
Buat dua direktori baru untuk Hadoop untuk menyimpan maklumat Namenode dan Datanode.
$ mkdir -p ~/hdfs/namenode ~/hdfs/datanode
Kemudian, edit fail berikut untuk memberitahu Hadoop di mana untuk mencari direktori tersebut:
$ nano ~/Hadoop-3.1.3/etc/Hadoop/HDFS-tapak.XML
Membuat perubahan berikut pada tapak HDFS.XML fail, sebelum menyimpan dan menutupnya:
DFS.Replikasi 1 DFS.nama.Fail dir: /// Home/Hadoop/HDFS/Namenode DFS.data.Fail dir: /// Home/Hadoop/HDFS/Datanode 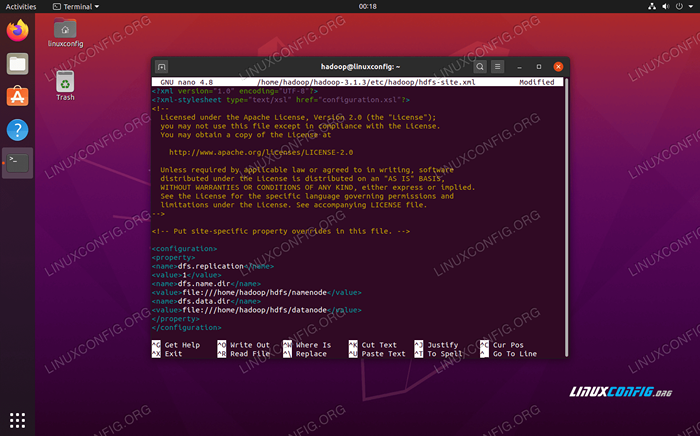 tapak HDFS.Perubahan fail konfigurasi XML
tapak HDFS.Perubahan fail konfigurasi XML Perubahan Konfigurasi di Laman Mapred.Fail XML
Buka fail konfigurasi MapReduce XML dengan arahan berikut:
$ nano ~/Hadoop-3.1.3/etc/Hadoop/Mapred-site.XML
Dan membuat perubahan berikut sebelum menyimpan dan menutup fail:
MapReduce.Rangka Kerja.Nama benang 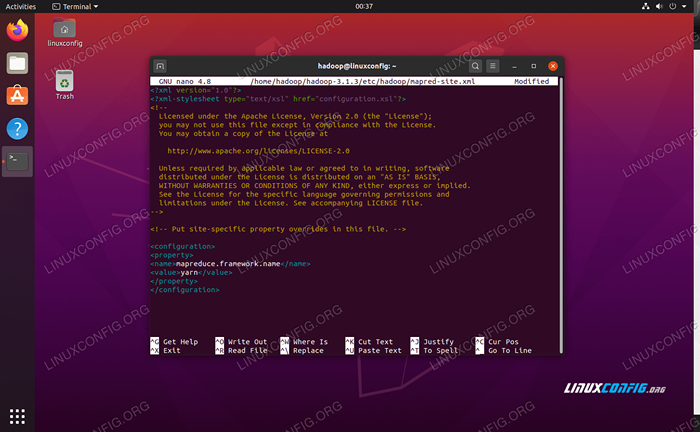 tapak peta.Perubahan fail konfigurasi XML
tapak peta.Perubahan fail konfigurasi XML Perubahan konfigurasi di tapak benang.Fail XML
Buka fail konfigurasi benang dengan arahan berikut:
$ nano ~/Hadoop-3.1.3/etc/Hadoop/tapak benang.XML
Tambahkan penyertaan berikut dalam fail ini, sebelum menyimpan perubahan dan menutupnya:
MapReduceyarn.Nodemanager.Aux-Services MapReduce_Shuffle 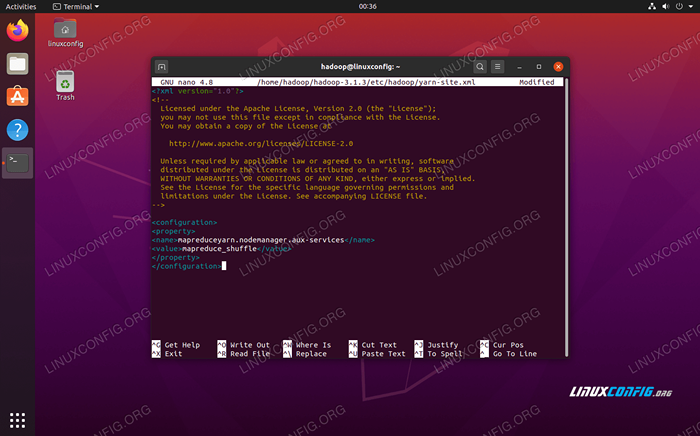 Fail konfigurasi tapak benang berubah
Fail konfigurasi tapak benang berubah Memulakan kelompok Hadoop
Sebelum menggunakan kluster untuk kali pertama, kita perlu memformat namenode. Anda boleh melakukannya dengan arahan berikut:
$ hdfs namenode -format
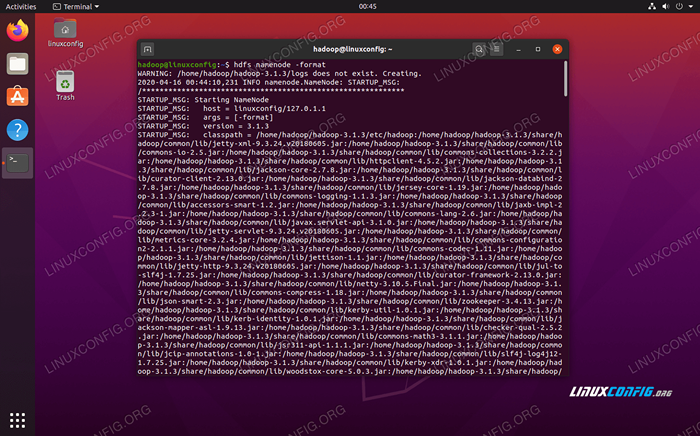 Memformat Namenode HDFS
Memformat Namenode HDFS Terminal anda akan meludahkan banyak maklumat. Selagi anda tidak melihat mesej ralat, anda boleh menganggapnya berjaya.
Seterusnya, mulakan HDF dengan menggunakan start-dfs.sh Skrip:
$ start-dfs.sh
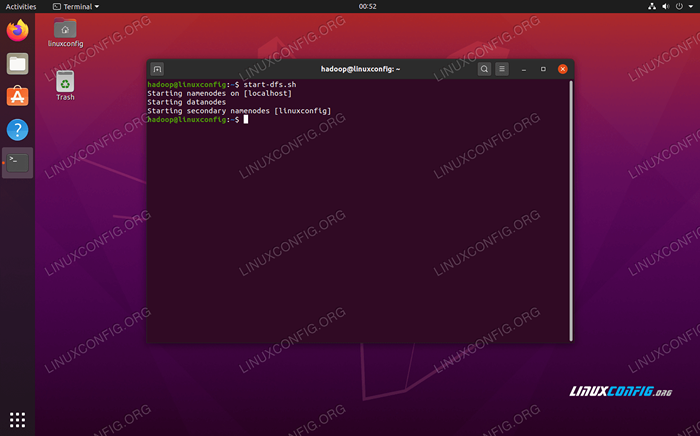 Jalankan Start-DFS.skrip sh
Jalankan Start-DFS.skrip sh Sekarang, mulakan perkhidmatan benang melalui Start-Yarn.sh Skrip:
$ start-yarn.sh
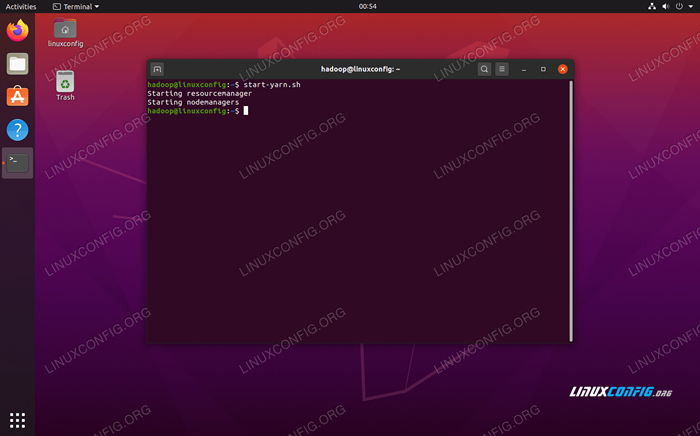 Jalankan Mula-Mula.skrip sh
Jalankan Mula-Mula.skrip sh Untuk mengesahkan semua perkhidmatan Hadoop/daemon dimulakan dengan jayanya, anda boleh menggunakan JPS perintah. Ini akan menunjukkan semua proses yang kini menggunakan Java yang sedang berjalan di sistem anda.
$ jps
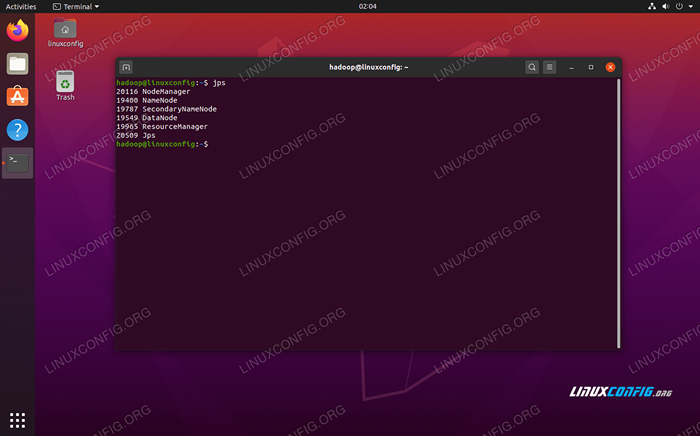 Jalankan JPS untuk melihat semua proses bergantung Java dan sahkan komponen Hadoop sedang berjalan
Jalankan JPS untuk melihat semua proses bergantung Java dan sahkan komponen Hadoop sedang berjalan Sekarang kita boleh menyemak versi Hadoop semasa dengan salah satu arahan berikut:
versi $ Hadoop
atau
$ HDFS versi
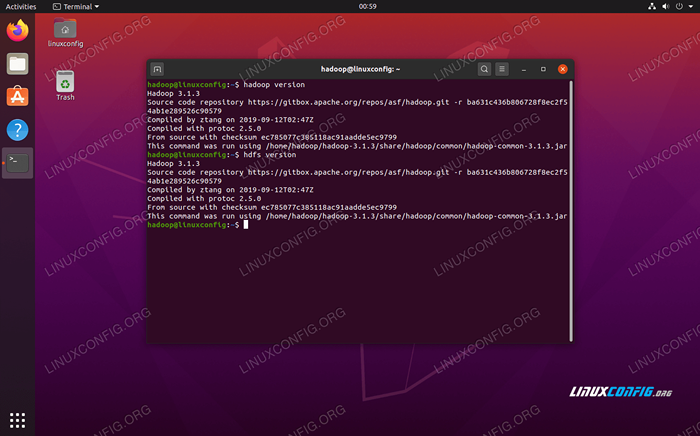 Mengesahkan pemasangan Hadoop dan versi semasa
Mengesahkan pemasangan Hadoop dan versi semasa Antara muka baris arahan HDFS
Baris arahan HDFS digunakan untuk mengakses HDFS dan membuat direktori atau mengeluarkan arahan lain untuk memanipulasi fail dan direktori. Gunakan sintaks perintah berikut untuk membuat beberapa direktori dan senaraikannya:
$ hdfs dfs -mkdir /test $ hdfs dfs -mkdir /hadooponubuntu $ hdfs dfs -ls /
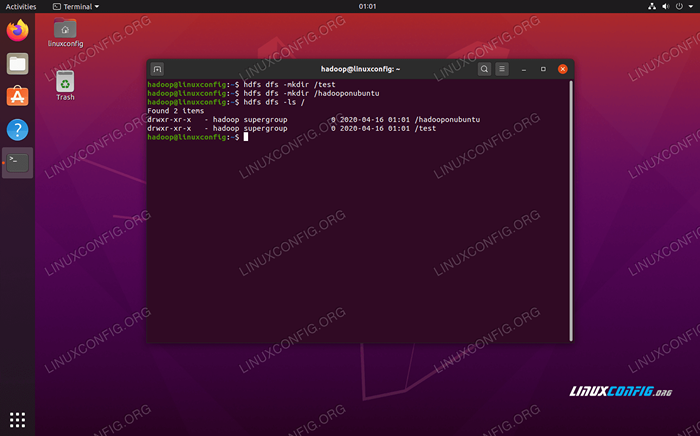 Berinteraksi dengan baris arahan HDFS
Berinteraksi dengan baris arahan HDFS Akses namenode dan benang dari penyemak imbas
Anda boleh mengakses kedua -dua UI web untuk Namenode dan Pengurus Sumber Benang melalui mana -mana pelayar pilihan anda, seperti Mozilla Firefox atau Google Chrome.
Untuk UI Web Namenode, navigasi ke http: // hadoop-hostname-or-ip: 50070
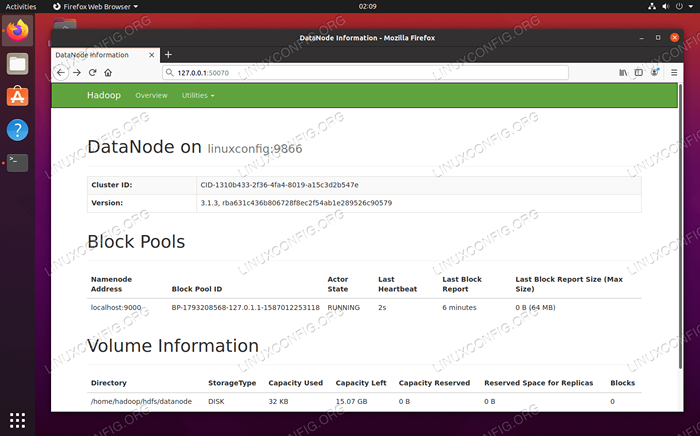 Antara muka web datanode untuk hadoop
Antara muka web datanode untuk hadoop Untuk mengakses antara muka web Pengurus Sumber Benang, yang akan memaparkan semua pekerjaan yang sedang dijalankan di kluster Hadoop, menavigasi ke http: // hadoop-hostname-or-ip: 8088
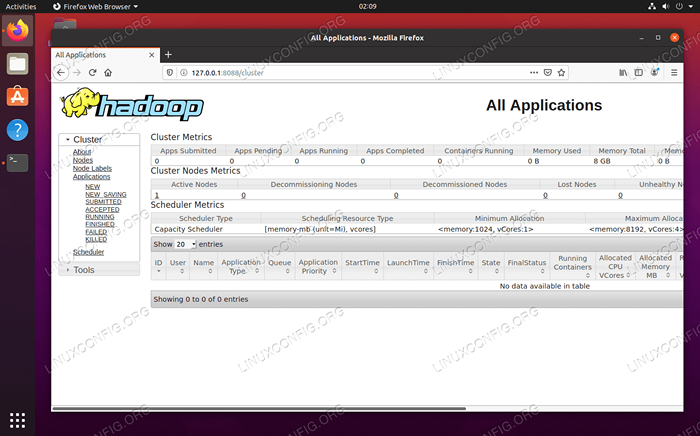 Antara Muka Web Pengurus Sumber Benang untuk Hadoop
Antara Muka Web Pengurus Sumber Benang untuk Hadoop Kesimpulan
Dalam artikel ini, kami melihat cara memasang Hadoop pada satu kluster nod tunggal di Ubuntu 20.04 Focal Fossa. Hadoop memberikan kami penyelesaian yang baik untuk berurusan dengan data besar, membolehkan kami menggunakan kelompok untuk penyimpanan dan pemprosesan data kami. Ia menjadikan kehidupan kita lebih mudah apabila bekerja dengan set data yang besar dengan konfigurasi fleksibel dan antara muka web yang mudah.
Tutorial Linux Berkaitan:
- Perkara yang hendak dipasang di Ubuntu 20.04
- Cara Membuat Kluster Kubernet
- Ubuntu 20.04 WordPress dengan pemasangan Apache
- Cara memasang kubernet di ubuntu 20.04 Focal Fossa Linux
- Cara Bekerja Dengan API Rest WooCommerce dengan Python
- Gelung bersarang dalam skrip bash
- Perkara yang perlu dilakukan setelah memasang ubuntu 20.04 Focal Fossa Linux
- Menguasai Gelung Skrip Bash
- Cara memasang Kubernet di Ubuntu 22.04 Jur -ubur Jammy ..
- Pengenalan kepada Automasi, Alat dan Teknik Linux