

Pengenalan kepada pengikis web python dan perpustakaan sup yang indah
- 4350
- 1396
- Noah Torp
Objektif
Belajar Cara Mengekstrak Maklumat Dari Halaman HTML Menggunakan Python dan Perpustakaan Sup Cantik.
Keperluan
- Pemahaman asas -asas pengaturcaraan berorientasikan objek dan objek
Konvensyen
- # - Memerlukan arahan Linux yang diberikan dengan keistimewaan akar sama ada
secara langsung sebagai pengguna akar atau dengan menggunakansudoperintah - $ - Memandangkan perintah Linux dilaksanakan sebagai pengguna yang tidak istimewa
Pengenalan
Pengikis Web adalah teknik yang terdiri daripada pengekstrakan data dari laman web melalui penggunaan perisian khusus. Dalam tutorial ini kita akan melihat bagaimana untuk melakukan pengikis web asas menggunakan Python dan Perpustakaan Sup yang Cantik. Kami akan menggunakannya python3 Menyasarkan laman utama Rotten Tomatoes, agregat ulasan dan berita yang terkenal untuk filem dan rancangan TV, sebagai sumber maklumat untuk latihan kami.
Pemasangan perpustakaan sup yang indah
Untuk melakukan pengikis kami, kami akan menggunakan perpustakaan Python sup yang indah, oleh itu perkara pertama yang perlu kita lakukan ialah memasangnya. Perpustakaan ini boleh didapati di repositori semua pengedaran utama GNU \ linux, oleh itu kami boleh memasangnya menggunakan pengurus pakej kegemaran kami, atau dengan menggunakan Pip, cara asli python untuk memasang pakej.
Jika penggunaan Pengurus Pakej Pengedaran lebih disukai dan kami menggunakan Fedora:
$ sudo DNF Pasang python3-beautifulsoup4
Pada Debian dan derivatifnya pakej itu dipanggil BeautifulSoup4:
$ sudo apt-get pemasangan cantiksoup4
Di Archilinux kita boleh memasangnya melalui Pacman:
$ sudo pacman -s python -beatufilusoup4
Sekiranya kita mahu menggunakan Pip, Sebaliknya, kita hanya boleh menjalankan:
$ PIP3 Pasang -Pengguna BeautifulSoup4
Dengan menjalankan arahan di atas dengan --pengguna Bendera, kami akan memasang versi terbaru perpustakaan sup yang indah hanya untuk pengguna kami, oleh itu tiada kebenaran root diperlukan. Sudah tentu anda boleh memutuskan untuk menggunakan PIP untuk memasang pakej di seluruh dunia, tetapi secara peribadi saya cenderung lebih suka pemasangan per-pengguna apabila tidak menggunakan Pengurus Pakej Pengedaran.
Objek yang indah
Mari kita mulakan: Perkara pertama yang ingin kita lakukan ialah membuat objek yang indah. Pembina BeautifulSoup menerima sama ada a tali atau pemegang fail sebagai hujah pertama. Yang terakhir adalah apa yang menarik minat kita: kita mempunyai URL halaman yang kita mahu mengikis, oleh itu kita akan menggunakan urlopen kaedah urllib.permintaan Perpustakaan (dipasang secara lalai): Kaedah ini mengembalikan objek seperti fail:
dari bs4 import cantik dari urllib.minta import urlopen dengan urlopen ('http: // www.Rottentomatoes.com ') sebagai laman utama: sup = indahSoup (laman utama) Pada ketika ini, sup kami sudah siap: sup objek mewakili dokumen secara keseluruhannya. Kita boleh mula menavigasi dan mengekstrak data yang kita mahu menggunakan kaedah dan sifat terbina dalam. Sebagai contoh, katakan kami ingin mengekstrak semua pautan yang terkandung dalam halaman: Kami tahu bahawa pautan diwakili oleh a Tag dalam HTML dan pautan sebenar terkandung di href atribut tag, jadi kita boleh menggunakan find_all Kaedah objek yang baru saja kami bina untuk menyelesaikan tugas kami:
untuk pautan dalam sup.find_all ('a'): cetak (pautan.dapatkan ('href')) Dengan menggunakan find_all kaedah dan menentukan a Sebagai hujah pertama, yang merupakan nama tag, kami mencari semua pautan di halaman. Untuk setiap pautan, kami kemudian mengambil dan mencetak nilai href atribut. Dalam indah, atribut elemen disimpan ke dalam kamus, oleh itu mengambilnya sangat mudah. Dalam kes ini kita menggunakan Dapatkan kaedah, tetapi kita boleh mengakses nilai atribut HREF walaupun dengan sintaks berikut: pautan ['href']. Kamus atribut yang lengkap itu sendiri terkandung dalam Attrs harta elemen. Kod di atas akan menghasilkan hasil berikut:
[...] https: // editorial.Rottentomatoes.com/https: // editorial.Rottentomatoes.com/24-frames/https: // editorial.Rottentomatoes.com/binge-guide/https: // editorial.Rottentomatoes.com/box-office-guru/https: // editorial.Rottentomatoes.com/pengkritik-konsensus/https: // editorial.Rottentomatoes.com/lima kegemaran-filem/https: // editorial.Rottentomatoes.com/sekarang streaming/https: // editorial.Rottentomatoes.com/pengarah ibu bapa/https: // editorial.Rottentomatoes.com/red-carpet-roundup/https: // editorial.Rottentomatoes.com/rt-on-dvd/https: // editorial.Rottentomatoes.com/the-simpsons-decade/https: // editorial.Rottentomatoes.com/sub-kultus/https: // editorial.Rottentomatoes.com/tech-talk/https: // editorial.Rottentomatoes.com/ total-recall/ [...]
Senarai ini lebih lama: di atas hanyalah ekstrak output, tetapi memberi anda idea. The find_all kaedah mengembalikan semua Tag objek yang sesuai dengan penapis yang ditentukan. Dalam kes kami, kami baru saja menetapkan nama tag yang sepatutnya dipadankan, dan tidak ada kriteria lain, jadi semua pautan dikembalikan: kami akan melihat dalam sekejap bagaimana untuk menyekat carian kami.
Kes Ujian: Mendapatkan semua tajuk "Box Office"
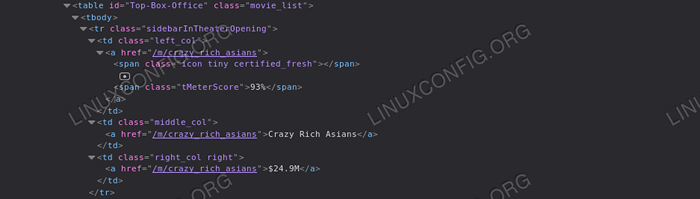
Mari kita melakukan pengikis yang lebih terhad. Katakan kami ingin mengambil semua tajuk filem yang muncul di bahagian "Box Office" di Rotten Tomatoes HomePage. Perkara pertama yang ingin kita lakukan ialah menganalisis halaman HTML untuk bahagian itu: berbuat demikian, kita dapat melihat bahawa elemen yang kita perlukan semuanya terkandung di dalam a Jadual elemen dengan "pejabat atas-kotak" ID:
Pejabat kotak teratas Kita juga dapat melihat bahawa setiap baris meja memegang maklumat mengenai filem: skor tajuk terkandung sebagai teks di dalam a rentang elemen dengan kelas "tmeterscore" di dalam sel pertama baris, sementara rentetan yang mewakili tajuk filem terkandung di dalam sel kedua, sebagai teks a tag. Akhirnya, sel terakhir mengandungi pautan dengan teks yang mewakili hasil box office filem. Dengan rujukan tersebut, kita dapat dengan mudah mengambil semua data yang kita mahukan:
dari bs4 import cantik dari urllib.minta import urlopen dengan urlopen ('https: // www.Rottentomatoes.com ') sebagai laman utama: sup = indahSoup (laman utama.baca (), 'html.parser ') # pertama kita menggunakan kaedah cari untuk mengambil jadual dengan' top-box-office 'id top_box_office_table = sup.cari ('jadual', 'id': 'top-box-office') # Daripada kami melelehkan setiap baris dan ekstrak maklumat filem untuk baris di top_box_office_table.find_all ('tr'): sel = baris.find_all ('td') tajuk = sel [1].mencari').get_text () wang = sel [2].mencari').get_text () skor = baris.cari ('span', 'class': 'tmeterscore').get_text () cetak ('0 - 1 (tomatometer: 2)'.Format (Tajuk, Wang, Skor)) Kod di atas akan menghasilkan hasil berikut:
Asia kaya gila - $ 24.9m (Tomatometer: 93%) MEG - $ 12.9m (Tomatometer: 46%) pembunuhan gembira - \ $ 9.6m (Tomatometer: 22%) Misi: Mustahil - Fallout - $ 8.2m (Tomatometer: 97%) Mile 22 - $ 6.5m (Tomatometer: 20%) Christopher Robin - $ 6.4m (Tomatometer: 70%) Alpha - $ 6.1m (Tomatometer: 83%) Blackkklansman - $ 5.2m (Tomatometer: 95%) Lelaki langsing - $ 2.9m (tomatometer: 7%) a.X.L. -- $ 2.8m (Tomatometer: 29%)
Kami memperkenalkan beberapa elemen baru, mari kita lihat mereka. Perkara pertama yang telah kami lakukan, adalah untuk mendapatkan Jadual dengan id 'atas-kotak', menggunakan cari kaedah. Kaedah ini berfungsi sama seperti find_all, Tetapi sementara yang terakhir mengembalikan senarai yang mengandungi perlawanan yang dijumpai, atau kosong jika tidak ada surat -menyurat, pulangan yang pertama selalu menjadi hasil pertama atau Tiada Sekiranya elemen dengan kriteria yang ditentukan tidak dijumpai.
Elemen pertama yang diberikan kepada cari kaedah adalah nama tag yang akan dipertimbangkan dalam carian, dalam kes ini Jadual. Sebagai hujah kedua, kami meluluskan kamus di mana setiap kunci mewakili atribut tag dengan nilai yang sepadan. Pasangan nilai utama yang disediakan dalam kamus mewakili kriteria yang mesti dipenuhi untuk pencarian kami untuk menghasilkan pertandingan. Dalam kes ini kami mencari ID atribut dengan nilai "atas-kotak". Perhatikan bahawa sejak masing -masing ID Mesti unik di halaman HTML, kami hanya boleh meninggalkan nama tag dan menggunakan sintaks alternatif ini:
top_box_office_table = sup.Cari (id = 'Of-box-Office') Sebaik sahaja kami mengambil jadual kami Tag objek, kami menggunakan find_all kaedah untuk mencari semua baris, dan berulang di atasnya. Untuk mendapatkan unsur -unsur lain, kami menggunakan prinsip yang sama. Kami juga menggunakan kaedah baru, get_text: ia mengembalikan hanya bahagian teks yang terkandung dalam tag, atau jika tidak ada yang ditentukan, di seluruh halaman. Sebagai contoh, mengetahui bahawa peratusan skor filem diwakili oleh teks yang terkandung di dalam rentang elemen dengan tmeterscore kelas, kami menggunakan get_text kaedah pada elemen untuk mendapatkannya.
Dalam contoh ini, kami hanya memaparkan data yang diambil dengan pemformatan yang sangat mudah, tetapi dalam senario dunia sebenar, kami mungkin ingin melakukan manipulasi lanjut, atau menyimpannya dalam pangkalan data.
Kesimpulan
Dalam tutorial ini kita hanya menggaruk permukaan apa yang boleh kita lakukan menggunakan python dan perpustakaan sup yang indah untuk melakukan pengikis web. Perpustakaan mengandungi banyak kaedah yang boleh anda gunakan untuk carian yang lebih halus atau lebih baik menavigasi halaman: untuk ini saya sangat mengesyorkan untuk merujuk dokumen rasmi yang ditulis dengan baik.
Tutorial Linux Berkaitan:
- Perkara yang hendak dipasang di Ubuntu 20.04
- Pengenalan kepada Automasi, Alat dan Teknik Linux
- Perkara yang perlu dilakukan setelah memasang ubuntu 20.04 Focal Fossa Linux
- Menguasai Gelung Skrip Bash
- Mint 20: Lebih baik daripada Ubuntu dan Microsoft Windows?
- Perintah Linux: Top 20 Perintah Paling Penting yang Anda Perlu ..
- Perintah Linux Asas
- Cara Membina Aplikasi TKInter Menggunakan Objek Berorientasikan ..
- Ubuntu 20.04 WordPress dengan pemasangan Apache
- Cara Gunung ISO di Linux