

Pasang kluster multinode Hadoop menggunakan CDH4 dalam RHEL/CentOS 6.5

- 3501
- 443
- Clarence Tromp
Hadoop adalah rangka kerja pemrograman sumber terbuka yang dibangunkan oleh Apache untuk memproses data besar. Ia menggunakan HDFS (Hadoop diedarkan sistem fail) untuk menyimpan data merentasi semua datanodes dalam kelompok dengan cara pengagihan dan model MapReduce untuk memproses data.
 Pasang kluster multinode Hadoop
Pasang kluster multinode Hadoop Namenode (Nn) adalah daemon induk yang mengawal HDFS dan JobTracker (Jt) adalah daemon tuan untuk enjin mapreduce.
Keperluan
Dalam tutorial ini saya menggunakan dua Centos 6.3 Vms 'tuan'Dan'nod'Viz. (tuan dan nod adalah nama tuan rumah saya). IP 'Master' adalah 172.21.17.175 dan nod ip adalah '172.21.17.188'. Arahan berikut juga berfungsi RHEL/Centos 6.x versi.
Pada tuan
[[dilindungi e -mel] ~]# hostname tuan
[[E -mel dilindungi] ~]# ifconfig | grep 'inet addr' | kepala -1 inet addr:172.21.17.175 Bcast: 172.21.19.255 Mask: 255.255.252.0
Pada nod
[[dilindungi e -mel] ~]# hostname nod
[[E -mel dilindungi] ~]# ifconfig | grep 'inet addr' | kepala -1 inet addr:172.21.17.188 Bcast: 172.21.19.255 Mask: 255.255.252.0
Pertama pastikan bahawa semua tuan rumah kluster ada di sana '/etc/hosts'Fail (pada setiap nod), jika anda tidak mempunyai DNS disediakan.
Pada tuan
[[dilindungi e -mel] ~]# kucing /etc /host 172.21.17.175 Master 172.21.17.188 Node
Pada nod
[[dilindungi e -mel] ~]# kucing /etc /host 172.21.17.197 Qabox 172.21.17.176 Ansible-Ground
Memasang Kluster Multinode Hadoop di CentOS
Kami menggunakan rasmi Cdh repositori untuk dipasang CDH4 Pada semua tuan rumah (tuan dan nod) dalam kumpulan.
Langkah 1: Muat turun Pasang Repositori CDH
Pergi ke halaman muat turun CDH rasmi dan ambil CDH4 (i.e. 4.6) versi atau anda boleh menggunakan berikut wget Perintah untuk memuat turun repositori dan pasangkannya.
Pada RHEL/CentOS 32-bit
# wget http: // arkib.Cloudera.com/cdh4/one-click-install/redhat/6/i386/cloudera-cdh-4-0.i386.rpm # yum --nogpgcheck localinstall cloudera-cdh-4-0.i386.rpm
Pada RHEL/CentOS 64-bit
# wget http: // arkib.Cloudera.com/cdh4/satu klik-install/redhat/6/x86_64/cloudera-cdh-4-0.x86_64.rpm # yum --nogpgcheck localinstall cloudera-cdh-4-0.x86_64.rpm
Sebelum memasang cluster multinode Hadoop, tambahkan kunci GPG awam Cloudera ke repositori anda dengan menjalankan salah satu arahan berikut mengikut seni bina sistem anda.
## pada sistem 32-bit ## # rpm --import http: // arkib.Cloudera.com/cdh4/redhat/6/i386/cdh/rpm-gpg-key-cloudera
## pada sistem 64-bit ## # rpm --import http: // arkib.Cloudera.com/cdh4/redhat/6/x86_64/cdh/rpm-gpg-key-cloudera
Langkah 2: Persediaan JobTracker & Namenode
Seterusnya, jalankan arahan berikut untuk memasang dan menyiapkan JobTracker dan NameNode pada Server Master.
[[dilindungi e-mel] ~]# yum membersihkan semua [[dilindungi e-mel] ~]# yum memasang hadoop-0.20-Mapreduce-Jobtracker
[[dilindungi e-mel] ~]# yum membersihkan semua [[dilindungi e-mel] ~]# yum memasang hadoop-hdfs-namenode
Langkah 3: Persediaan Node Nama Menengah
Sekali lagi, jalankan arahan berikut pada pelayan induk untuk menyiapkan nod nama sekunder.
[[dilindungi e-mel] ~]# yum membersihkan semua [[dilindungi e-mel] ~]# yum Pasang Hadoop-HDFS-Secondarynam
Langkah 4: Persediaan TaskTracker & Datanode
Seterusnya, persediaan TaskTracker & Datanode pada semua host cluster (nod) kecuali JobTracker, Namenode, dan menengah (atau siap sedia) Namenode Hosts (pada nod dalam kes ini).
[[dilindungi e-mel] ~]# yum membersihkan semua [[dilindungi e-mel] ~]# yum memasang hadoop-0.20-Mapreduce-Tasktracker Hadoop-HDFS-Datanode
Langkah 5: Persediaan Pelanggan Hadoop
Anda boleh memasang klien Hadoop pada mesin yang berasingan (dalam kes ini saya telah memasangnya di Datanode, anda boleh memasangnya di mana -mana mesin).
[[dilindungi e-mel] ~]# yum Pasang Hadoop-client
Langkah 6: Menyebarkan HDF pada nod
Sekarang jika kita selesai dengan langkah -langkah di atas mari kita bergerak ke hadapan untuk menggunakan HDFS (dilakukan pada semua nod).
Salin konfigurasi lalai ke /etc/Hadoop direktori (pada setiap nod dalam kluster).
[[dilindungi e -mel] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
[[dilindungi e -mel] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
Gunakan alternatif Perintah untuk menetapkan direktori tersuai anda, seperti berikut (pada setiap nod dalam kluster).
[[E-mel dilindungi] ~]# Alternatif --Verbose-Install/etc/Hadoop/Conf Hadoop-Conf/etc/Hadoop/Conf.my_cluster 50 bacaan/var/lib/alternatif/hadoop-conf [[dilindungi e-mel] ~]# alternatif-set Hadoop-conf/etc/Hadoop/conf.my_cluster
[[E-mel dilindungi] ~]# Alternatif --Verbose-Install/etc/Hadoop/Conf Hadoop-Conf/etc/Hadoop/Conf.my_cluster 50 bacaan/var/lib/alternatif/hadoop-conf [[dilindungi e-mel] ~]# alternatif-set Hadoop-conf/etc/Hadoop/conf.my_cluster
Langkah 7: Menyesuaikan fail konfigurasi
Sekarang buka 'tapak teras.XML'Fail dan kemas kini "fs.defaultfs"Pada setiap nod dalam kelompok.
[[dilindungi e-mel] conf]# kucing/etc/hadoop/conf/core-site.XML
fs.defaultfs HDFS: // Master/
[[dilindungi e-mel] conf]# kucing/etc/hadoop/conf/core-site.XML
fs.defaultfs HDFS: // Master/
Kemas kini seterusnya "DFS.keizinan.SuperUserGroup"Dalam tapak HDFS.XML pada setiap nod dalam kelompok.
[[dilindungi e-mel] conf]# kucing/etc/hadoop/conf/hdfs-site.XML
DFS.nama.dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/name DFS.keizinan.SuperUserGroup Hadoop
[[dilindungi e-mel] conf]# kucing/etc/hadoop/conf/hdfs-site.XML
DFS.nama.dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/name DFS.keizinan.SuperUserGroup Hadoop
Catatan: Pastikan bahawa, konfigurasi di atas hadir pada semua nod (lakukan pada satu nod dan lari SCP Untuk menyalin selebihnya nod).
Langkah 8: Mengkonfigurasi Direktori Penyimpanan Tempatan
Kemas kini "DFS.nama.dir atau dfs.namenode.nama.dir 'di tapak hdfs.xml 'di namenode (pada tuan dan nod). Sila ubah nilai seperti yang diserlahkan.
[[dilindungi e-mel] conf]# kucing/etc/hadoop/conf/hdfs-site.XML
DFS.namenode.nama.dir fail: /// data/1/dfs/nn,/nfsmount/dfs/nn
[[dilindungi e-mel] conf]# kucing/etc/hadoop/conf/hdfs-site.XML
DFS.DataNode.data.dir Fail: /// Data/1/dfs/dn,/data/2/dfs/dn,/data/3/dfs/dn
Langkah 9: Buat Direktori & Urus Kebenaran
Jalankan arahan di bawah untuk membuat struktur direktori & mengurus keizinan pengguna pada mesin Namenode (Master) dan Datanode (Node).
[[dilindungi e -mel]]# mkdir -p/data/1/dfs/nn/nfsmount/dfs/nn [[e -mel dilindungi]]# chmod 700/data/1/dfs/nn/nfsmount/dfs/nn/nn/nn/nn
[[dilindungi e -mel]]# mkdir -p/data/1/dfs/dn/data/2/dfs/dn/data/3/dfs/dn/data/4/dfs/dn [[dilindungi e -mel]]# chown]# chown]# chown]# chown]# chown]# chown]# chown]# chown]# chown] -R HDFS: HDFS/Data/1/DFS/NN/NFSMOUNT/DFS/NN/DATA/1/DFS/DN/DATA/2/DFS/DN/DATA/3/DFS/DN/DAT/4/DFS/ dn
Format namenode (pada tuan), dengan mengeluarkan arahan berikut.
[[dilindungi e -mel] conf]# sudo -u hdfs hdfs namenode -format
Langkah 10: Mengkonfigurasi namenode sekunder
Tambahkan harta berikut ke tapak HDFS.XML fail dan ganti nilai seperti yang ditunjukkan pada tuan.
DFS.namenode.HTTP-Address 172.21.17.175: 50070 Alamat dan port di mana UI Namenode akan mendengar.
Catatan: Dalam nilai kes kami hendaklah alamat IP tuan rumah vm.
Sekarang mari kita gunakan MRV1 (peta-mengurangkan versi 1). Buka 'tapak peta.XML'Nilai berikut fail seperti yang ditunjukkan.
[[dilindungi e-mel] conf]# CP HDFS-Site.XML MAPRED-SITE.xml [[dilindungi e-mel] conf]# vi mapred-site.xml [[dilindungi e-mel] conf]# kucing peta-tapak.XML
peta.kerja.Master Tracker: 8021
Seterusnya, salin 'tapak peta.XML'Fail ke mesin nod menggunakan arahan SCP berikut.
[[dilindungi e-mel] conf]# scp/etc/hadoop/conf/mapred-site.Nod XML:/etc/Hadoop/conf/mapred-site.XML 100% 200 0.2kb/s 00:00
Sekarang konfigurasikan direktori penyimpanan tempatan untuk digunakan oleh daemon MRV1. Sekali lagi buka 'tapak peta.XML'Fail dan buat perubahan seperti yang ditunjukkan di bawah untuk setiap TaskTracker.
 Mapred.tempatan.dir â/data/1/mapred/local,/data/2/mapred/local,/data/3/mapred/local
Setelah menentukan direktori ini di 'tapak peta.XML'Fail, anda mesti membuat direktori dan memberikan kebenaran fail yang betul kepada mereka pada setiap nod dalam kelompok anda.
mkdir -p/data/1/mapred/local/data/2/mapred/local/data/3/mapred/local/data/4/mapred/local chown -r mapred: hadoop/data/1/mapred/local/ Data/2/Mapred/Local/Data/3/Mapred/Local/Data/4/Mapred/Local
Langkah 10: Mulakan HDFS
Sekarang jalankan arahan berikut untuk memulakan HDF pada setiap nod dalam kelompok.
[[dilindungi e -mel] conf]# untuk x dalam 'cd /etc /init.d; ls Hadoop-hdfs-*'; Adakah perkhidmatan sudo $ x start; selesai
[[dilindungi e -mel] conf]# untuk x dalam 'cd /etc /init.d; ls Hadoop-hdfs-*'; Adakah perkhidmatan sudo $ x start; selesai
Langkah 11: Buat Direktori HDFS /TMP dan MapReduce /VAR
Ia dikehendaki membuat /TMP dengan kebenaran yang betul seperti yang disebutkan di bawah.
[[E -mel dilindungi] conf]# sudo -u hdfs hadoop fs -mkdir /tmp [[e -mel dilindungi] conf]# sudo -u hdfs hadoop fs -chmod -r 1777 /tmp
[[dilindungi e -mel] conf]# sudo -u hdfs hadoop fs -mkdir -p/var/lib/hadoop -hdfs/cache/mapred/mapred/staging [[dilindungi e -mel] conf]# sudo -u hdfs hadoop fs -chmod 1777 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging [[email protected] conf]# sudo -u hdfs hadoop fs -chown -R mapred /var/lib/hadoop-hdfs/cache/mapred
Sekarang sahkan struktur fail HDFS.
[[E-mel dilindungi] ode conf]# sudo -u hdfs hadoop fs -ls -r / drwxrwxrwt-hdfs hadoop 0 2014-05-29 09:58 / tmp drwxr-xr-x-hdfs hadoop 0 2014-05-29 09 : 59 /var drwxr-xr-x-hdfs hadoop 0 2014-05-29 09:59 /var /lib drwxr-xr-x-hdfs hadoop 0 2014-05-29 09:59 /var /lib /hadoop-hdfs DRWXR-XR-X-HDFS Hadoop 0 2014-05-29 09:59/var/lib/Hadoop-HDFS/Cache Drwxr-xr-x-Mapred Hadoop 0 2014-05-29 09:59/var/lib/lib/lib/lib/lib/lib/lib/lib/lib/lib/lib/lib/lib/lib/lib/lib -hdfs/cache/mapred drwxr-xr-x-Mapred Hadoop 0 2014-05-29 09:59/var/lib/hadoop-hdfs/cache/mapred/mapred drwxrwxrwt-Mapred Hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred/pementasan
Setelah anda memulakan HDFS dan buat '/TMP', tetapi sebelum anda memulakan JobTracker sila buat direktori HDFS yang ditentukan oleh' Mapred.sistem.parameter dir '(secara lalai $ Hadoop.TMP.dir/mapred/sistem dan menukar pemilik ke mapred.
[[e -mel dilindungi] conf]# sudo -u hdfs hadoop fs -mkdir/tmp/mapred/system [[e -mel dilindungi] conf]# sudo -u hdfs hadoop fs -chown mapred: hadoop/tmp/mapred/sistem
Langkah 12: Mula MapReduce
Untuk memulakan MapReduce: Sila mulakan perkhidmatan TT dan JT.
Pada setiap sistem TaskTracker
[[dilindungi e-mel] conf]# Perkhidmatan Hadoop-0.20-Mapreduce-TaskTracker Memulakan TaskTracker: [OK] Memulakan TaskTracker, Logging To/Var/Log/Hadoop-0.20-Mapreduce/Hadoop-Hadoop-TaskTracker-node.keluar
Di sistem JobTracker
[[dilindungi e-mel] conf]# Perkhidmatan Hadoop-0.20-Mapreduce-Jobtracker Mula Memulakan JobTracker: [OK] Memulakan JobTracker, Logging to/Var/Log/Hadoop-0.20-Mapreduce/Hadoop-Hadoop-Jobtracker-Master.keluar
Seterusnya, buat direktori rumah untuk setiap pengguna Hadoop. Adalah disyorkan bahawa anda melakukan ini pada namenode; sebagai contoh.
[[dilindungi e -mel] conf]# sudo -u hdfs hadoop fs -mkdirâ /user /[[e -mel dilindungi] conf]# sudo -u hdfs hadoop fs -chown /user /user /
Catatan: di mana adalah nama pengguna linux bagi setiap pengguna.
Sebagai alternatif, anda boleh membuat direktori rumah seperti berikut.
[[dilindungi e -mel] conf]# sudo -u hdfs hadoop fs -mkdir /user /$ user [[e -mel dilindungi] conf]# sudo -u hdfs hadoop fs -chown $ user /user /$ user
Langkah 13: Buka JT, NN UI dari penyemak imbas
Buka penyemak imbas anda dan taipkan URL sebagai http: // ip_address_of_namenode: 50070 untuk mengakses namenode.
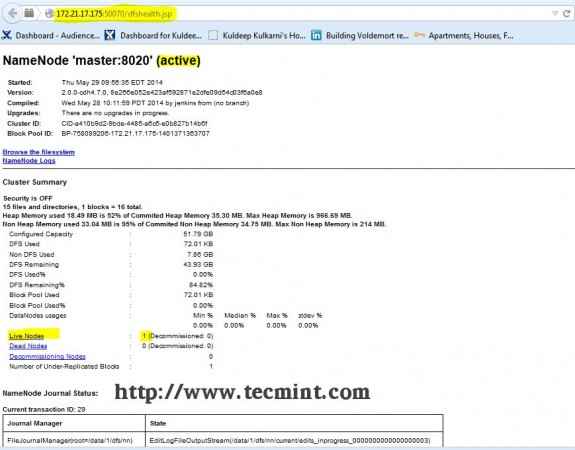 Hadoop Namenode Interface
Hadoop Namenode Interface Buka tab lain di penyemak imbas anda dan taipkan URL sebagai http: // ip_address_of_jobtracker: 50030 untuk mengakses JobTracker.
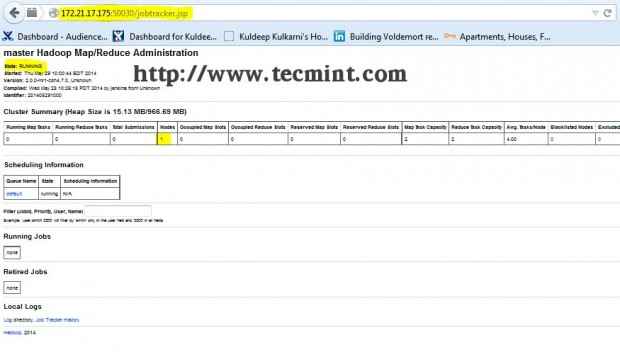 Peta Hadoop/Mengurangkan Pentadbiran
Peta Hadoop/Mengurangkan Pentadbiran Prosedur ini telah berjaya diuji RHEL/CENTOS 5.X/6.X. Sila komen di bawah jika anda menghadapi sebarang masalah dengan pemasangan, saya akan membantu anda dengan penyelesaiannya.
- « Buat laman web perkongsian video anda sendiri menggunakan 'CumulusClips Script' di Linux
- Membuat tuan rumah maya, menjana sijil & kunci SSL dan membolehkan CGI Gateway di Gentoo Linux »