

Cara Menyiapkan Hadoop di Ubuntu 18.04 & 16.04 LTS

- 1252
- 14
- Dale Harris II
Apache Hadoop 3.1 mempunyai penambahbaikan ketara yang banyak membetulkan pepijat berbanding stabil sebelumnya 3.0 Siaran. Versi ini mempunyai banyak penambahbaikan dalam HDFS dan MapReduce. Tutorial ini akan membantu anda memasang dan mengkonfigurasi Hadoop 3.1.2 Kluster tunggal-nod pada Ubuntu 18.04, 16.04 LTS dan Sistem Linuxmint. Artikel ini telah diuji dengan Ubuntu 18.04 LTS.
Langkah 1 - Prerequsities
Java adalah keperluan utama untuk menjalankan Hadoop pada mana -mana sistem, jadi pastikan anda memasang Java pada sistem anda menggunakan arahan berikut. Sekiranya anda tidak memasang Java pada sistem anda, gunakan salah satu pautan berikut untuk memasangnya terlebih dahulu.
- Pasang Oracle Java 11 di Ubuntu 18.04 LTS (Bionic)
- Pasang Oracle Java 11 di Ubuntu 16.04 LTS (xenial)
Langkah 2 - Buat Pengguna untuk Haddop
Kami mengesyorkan membuat akaun biasa (atau akar) untuk Hadoop bekerja. Untuk membuat akaun menggunakan arahan berikut.
Adduser Hadoop
Setelah membuat akaun, ia juga perlu menyediakan SSH berasaskan utama ke akaunnya sendiri. Untuk melakukan penggunaan ini melaksanakan arahan berikut.
su -Hadoop ssh -keygen -t rsa -p "-f ~/.ssh/id_rsa kucing ~/.SSH/ID_RSA.pub >> ~/.SSH/Authorized_keys chmod 0600 ~/.SSH/Authorized_keys
Sekarang, SSH ke localhost dengan pengguna Hadoop. Ini tidak boleh meminta kata laluan tetapi kali pertama ia akan meminta untuk menambah RSA ke senarai tuan rumah yang diketahui.
SSH Localhost Exit
Langkah 3 - Muat turun Arkib Sumber Hadoop
Dalam langkah ini, muat turun Hadoop 3.1 fail arkib sumber menggunakan arahan di bawah. Anda juga boleh memilih cermin muat turun alternatif untuk meningkatkan kelajuan muat turun.
cd ~ wget http: // www-eu.Apache.Org/Dist/Hadoop/Common/Hadoop-3.1.2/Hadoop-3.1.2.tar.GZ TAR XZF HADOOP-3.1.2.tar.GZ MV Hadoop-3.1.2 Hadoop
Langkah 4 - Persediaan Mod Hadoop Pseudo -Distribusi
4.1. Persediaan Pembolehubah Persekitaran Hadoop
Persediaan pembolehubah persekitaran yang digunakan oleh Hadoop. Edit ~/.Bashrc fail dan tambah nilai berikut pada akhir fail.
eksport hadoop_home =/home/hadoop/hadoop eksport Hadoop_install = $ Hadoop_Home Export Hadoop_Mapred_Home = $ Hadoop_Home Export Hadoop_Common_Home = $ Hadoop_Home Export Hadoop_Hdfs_Home = $ HADOOP_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_HOME_Home HADOOP_HOME/SBIN: $ HADOOP_HOME/BIN
Kemudian, gunakan perubahan dalam persekitaran berjalan semasa
sumber ~/.Bashrc
Sekarang edit $ Hadoop_Home/etc/Hadoop/Hadoop-ENV.sh fail dan tetapkan Java_home pembolehubah persekitaran. Tukar laluan Java mengikut pemasangan pada sistem anda. Laluan ini mungkin berbeza mengikut versi sistem operasi dan sumber pemasangan anda. Oleh itu, pastikan anda menggunakan jalan yang betul.
Vim $ Hadoop_Home/etc/Hadoop/Hadoop-ENV.sh
Kemas kini di bawah entri:
Eksport java_home =/usr/lib/jvm/java-11-oracle
4.2. Persediaan Fail Konfigurasi Hadoop
Hadoop mempunyai banyak fail konfigurasi, yang perlu mengkonfigurasi mengikut keperluan infrastruktur Hadoop anda. Mari kita mulakan dengan konfigurasi dengan persediaan kluster nod tunggal Hadoop asas. Pertama, navigasi ke lokasi di bawah
CD $ Hadoop_Home/etc/Hadoop
Edit tapak teras.XML
fs.lalai.Nama HDFS: // Localhost: 9000
Edit tapak HDFS.XML
DFS.Replikasi 1 DFS.nama.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/Namenode DFS.data.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode
Edit tapak Mapred.XML
MapReduce.Rangka Kerja.Nama benang
Edit tapak benang.XML
Benang.Nodemanager.Aux-Services MapReduce_Shuffle
4.3. Format namenode
Sekarang format namenode menggunakan arahan berikut, pastikan direktori penyimpanan adalah
HDFS namenode -Format
Output Contoh:
Amaran:/rumah/hadoop/hadoop/log tidak wujud. Mencipta. 2018-05-02 17: 52: 09,678 Maklumat Namenode.Namenode: startup_msg: /*********************************************** *************** startup_msg: Memulakan namenode startup_msg: host = tecadmin/127.0.1.1 startup_msg: args = [-format] startup_msg: versi = 3.1.2 ... 2018-05-02 17: 52: 13,717 maklumat biasa.Penyimpanan: Direktori Penyimpanan/Rumah/Hadoop/Hadoopdata/HDFS/Namenode telah berjaya diformat. 2018-05-02 17: 52: 13,806 Maklumat Namenode.FSImageFormatProtobuf: Menyimpan Fail Imej/Laman Utama/Hadoop/Hadoopdata/HDFS/Namenode/Current/FSImage.CKPT_00000000000000000000000 Menggunakan No Mampatan 2018-05-02 17: 52: 14,161 Info Namenode.FSImageFormatProtobuf: Fail Imej/Laman Utama/Hadoop/Hadoopdata/HDFS/Namenode/Current/FSImage.CKPT_000000000000000000000 saiz 391 bait disimpan dalam 0 saat . 2018-05-02 17: 52: 14,224 Info Namenode.NnstorageretentionManager: akan mengekalkan 1 imej dengan txid> = 0 2018-05-02 17: 52: 14,282 Info Namenode.Namenode: shutdown_msg: /*********************************************** ***************** shutdown_msg: Menutup namenode di Tecadmin/127.0.1.1 ******************************************************* *************/
Langkah 5 - Mula Cluster Hadoop
Mari mulakan cluster Hadoop anda menggunakan skrip yang disediakan oleh Hadoop. Cukup navigasi ke direktori $ hadoop_home/sbin anda dan laksanakan skrip satu demi satu.
CD $ HADOOP_HOME/SBIN/
Sekarang laksanakan start-dfs.sh Skrip.
./start-dfs.sh
Kemudian laksanakan Start-Yarn.sh Skrip.
./Start-Yarn.sh
Langkah 6 - Akses Perkhidmatan Hadoop dalam Penyemak Imbas
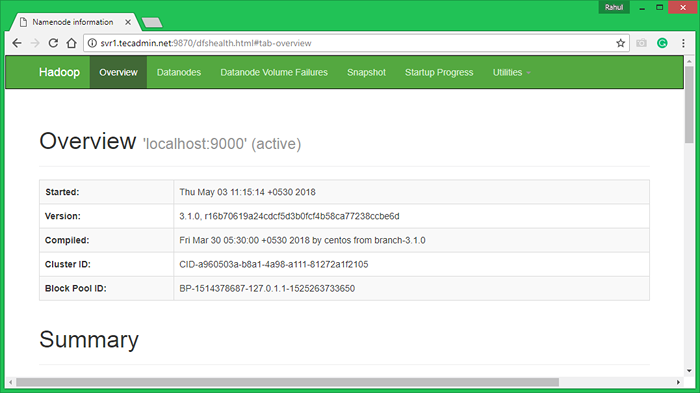
Hadoop Namenode bermula pada port lalai 9870. Akses pelayan anda di port 9870 di pelayar web kegemaran anda.
http: // svr1.Tecadmin.Bersih: 9870/
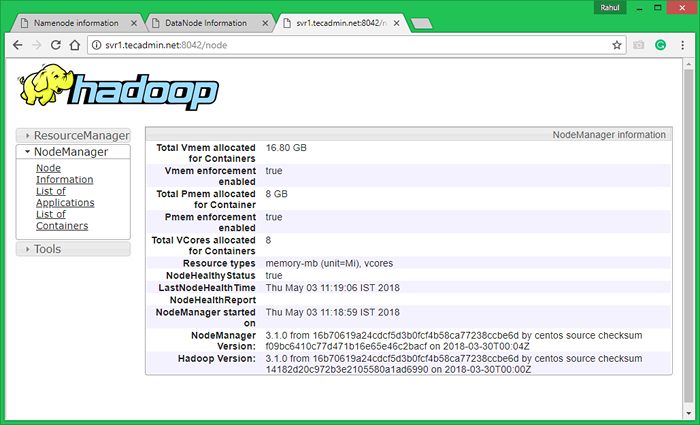
Sekarang akses port 8042 untuk mendapatkan maklumat mengenai kelompok dan semua aplikasi
http: // svr1.Tecadmin.Bersih: 8042/
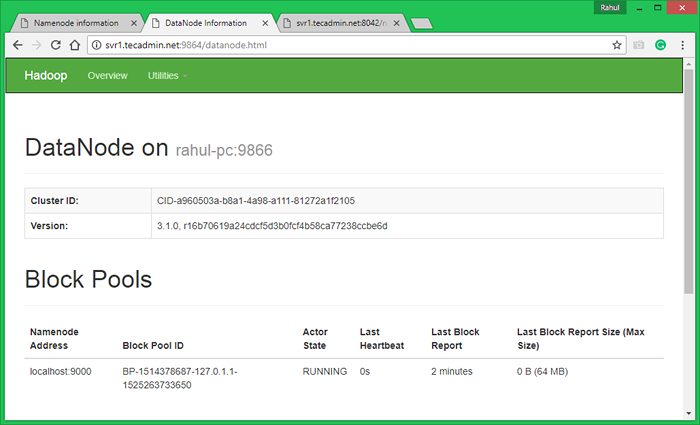
Port Akses 9864 untuk mendapatkan butiran mengenai nod Hadoop anda.
http: // svr1.Tecadmin.Bersih: 9864/
Langkah 7 - Uji persediaan nod tunggal Hadoop
7.1. Buat direktori HDFS diperlukan menggunakan arahan berikut.
BIN/HDFS DFS -MKDIR/Pengguna BIN/HDFS DFS -MKDIR/USER/HADOOP
7.2. Salin semua fail dari sistem fail tempatan/var/log/httpd ke sistem fail yang diedarkan Hadoop menggunakan arahan di bawah
BIN/HDFS DFS -PUT/VAR/LOG/APACHE2 LOGS
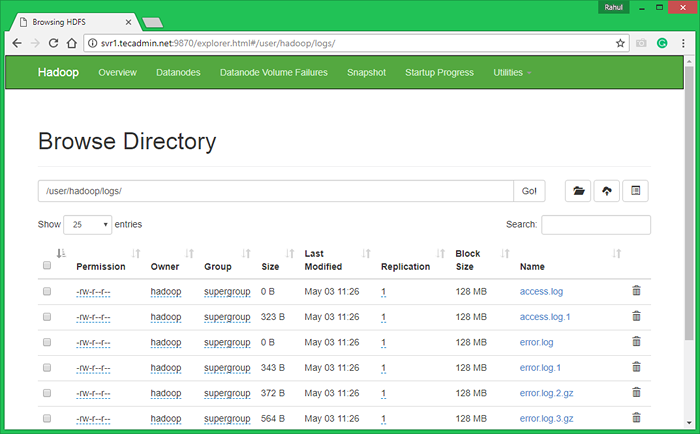
7.3. Semak Hadoop Sistem Fail Mengedarkan dengan membuka URL di bawah URL dalam penyemak imbas. Anda akan melihat folder Apache2 dalam senarai. Klik pada nama folder untuk dibuka dan anda akan menemui semua fail log di sana.
http: // svr1.Tecadmin.Bersih: 9870/Explorer.html#/user/hadoop/log/
7.4 - Sekarang salin direktori log untuk sistem fail yang diedarkan Hadoop ke sistem fail tempatan.
bin/hdfs DFS -get logs/tmp/logs ls -l/tmp/log/
Anda juga boleh menyemak tutorial ini untuk menjalankan contoh kerja WordCount MapReduce menggunakan baris arahan.
- « Cara Mengesan Persekitaran Desktop di Linux Command Rine
- Cara memuat turun dan memuat naik fail dengan arahan sftp »