

Cara memasang percikan pada rhel 8
- 1450
- 278
- Noah Torp
Apache Spark adalah sistem pengkomputeran yang diedarkan. Ia terdiri daripada tuan dan satu atau lebih hamba, di mana tuan mengedarkan kerja di kalangan budak -budak, sehingga memberikan keupayaan untuk menggunakan banyak komputer kami untuk bekerja pada satu tugas. Seseorang dapat meneka bahawa ini adalah alat yang berkuasa di mana tugas memerlukan pengiraan yang besar untuk disiapkan, tetapi boleh dibahagikan kepada langkah -langkah yang lebih kecil yang dapat ditolak ke hamba untuk bekerja. Sebaik sahaja kelompok kami berjalan dan berjalan, kami boleh menulis program untuk menjalankannya di Python, Java, dan Scala.
Dalam tutorial ini, kami akan bekerja pada mesin tunggal yang menjalankan Red Hat Enterprise Linux 8, dan akan memasang Master Spark dan Hamba ke mesin yang sama, tetapi perlu diingat bahawa langkah -langkah yang menggambarkan persediaan hamba boleh digunakan untuk beberapa komputer, dengan itu mewujudkan kelompok sebenar yang dapat memproses beban kerja yang berat. Kami juga akan menambah fail unit yang diperlukan untuk pengurusan, dan menjalankan contoh mudah terhadap kluster yang dihantar dengan pakej yang diedarkan untuk memastikan sistem kami beroperasi.
Dalam tutorial ini anda akan belajar:
- Cara Memasang Master Spark dan Hamba
- Cara Menambah Fail Unit Systemd
- Cara Mengesahkan Sambungan Master-Hamba yang Berjaya
- Cara menjalankan pekerjaan contoh mudah di kluster
Spark Shell dengan Pyspark. Keperluan perisian dan konvensyen yang digunakan
| Kategori | Keperluan, konvensyen atau versi perisian yang digunakan |
|---|---|
| Sistem | Red Hat Enterprise Linux 8 |
| Perisian | Apache Spark 2.4.0 |
| Yang lain | Akses istimewa ke sistem linux anda sebagai akar atau melalui sudo perintah. |
| Konvensyen | # - Memerlukan arahan Linux yang diberikan untuk dilaksanakan dengan keistimewaan akar sama ada secara langsung sebagai pengguna root atau dengan menggunakan sudo perintah$ - Memerlukan arahan Linux yang diberikan sebagai pengguna yang tidak layak |
Cara Memasang Spark Pada Redhat 8 Langkah demi Langkah Arahan
Apache Spark berjalan di JVM (Java Virtual Machine), jadi pemasangan Java 8 berfungsi diperlukan untuk aplikasi yang dijalankan. Selain itu, terdapat banyak cengkerang yang dihantar dalam pakej, salah satunya adalah pyspark, cangkang berasaskan python. Untuk bekerja dengan itu, anda juga memerlukan Python 2 yang dipasang dan disediakan.
- Untuk mendapatkan URL pakej terbaru Spark, kita perlu melawat laman muat turun Spark. Kami perlu memilih cermin yang paling dekat dengan lokasi kami, dan menyalin URL yang disediakan oleh laman muat turun. Ini juga bermaksud bahawa URL anda mungkin berbeza dari contoh di bawah. Kami akan memasang pakej di bawah
/Memilih/, Oleh itu, kita memasuki direktori sebagaiakar:# CD /OPT
Dan memberi makan url yang diarahkan ke
wgetUntuk mendapatkan pakej:# wget https: // www-eu.Apache.org/dist/percikan/percikan-2.4.0/Spark-2.4.0-bin-Hadoop2.7.TGZ
- Kami akan membongkar tarball:
# tar -xvf Spark -2.4.0-bin-Hadoop2.7.TGZ
- Dan buat symlink untuk menjadikan jalan kita lebih mudah diingat dalam langkah seterusnya:
# ln -s /opt /spark -2.4.0-bin-Hadoop2.7 /opt /percikan api
- Kami membuat pengguna yang tidak istimewa yang akan menjalankan kedua-dua aplikasi, tuan dan hamba:
# UserAdd Spark
Dan tetapkannya sebagai pemilik keseluruhan
/memilih/percikan apiDirektori, secara rekursif:# Chown -R Spark: Spark /Opt /Spark*
- Kami membuat a
sistemdfail unit/etc/Systemd/System/Spark-Master.perkhidmatanuntuk perkhidmatan induk dengan kandungan berikut:
Salinan[Unit] Keterangan = Apache Spark Master selepas = Rangkaian.Sasaran [Service] Type = Forking user = Spark Group = Spark Execstart =/Opt/Spark/Sbin/Start-Master.SH EXECSTOP =/OPT/SPARK/SBIN/STOP-MASTER.SH [Pasang] Wanteby = Multi-User.sasaranDan juga satu untuk perkhidmatan hamba yang akan
/etc/Systemd/System/Spark-Slave.perkhidmatan.perkhidmatandengan kandungan di bawah:
Salinan[Unit] Keterangan = Apache Spark Hamba Selepas = Rangkaian.sasaran [perkhidmatan] jenis = forking user = Spark Group = Spark execstart =/opt/spark/sbin/start-hamba.sh spark: // rhel8lab.Linuxconfig.org: 7077 execstop =/opt/spark/sbin/stop-slave.SH [Pasang] Wanteby = Multi-User.sasaranPerhatikan URL Spark yang diserlahkan. Ini dibina dengan
Spark: //: 7077, Dalam kes ini mesin makmal yang akan menjalankan tuan mempunyai nama hosRhel8lab.Linuxconfig.org. Nama tuan anda akan berbeza. Setiap hamba mesti dapat menyelesaikan nama hos ini, dan sampai ke tuan di pelabuhan yang ditentukan, yang merupakan pelabuhan7077Secara lalai. - Dengan fail perkhidmatan di tempat, kita perlu bertanya
sistemdUntuk membacanya semula:# Systemctl Daemon-Reload
- Kita boleh memulakan tuan pencucuh kita dengan
sistemd:# Systemctl Mula Spark-Master.perkhidmatan
- Untuk mengesahkan tuan kita berjalan dan berfungsi, kita boleh menggunakan status SystemD:
# Systemctl Status Spark-Master.Perkhidmatan Spark-Master.Perkhidmatan - Apache Spark Master Loaded: Loaded (/etc/Systemd/System/Spark -Master.perkhidmatan; dilumpuhkan; Pratetap Vendor: Dilumpuhkan) Aktif: Aktif (Berlari) Sejak Jum 2019-01-11 16:30:03 CET; 53min yang lalu Proses: 3308 execstop =/opt/percikan/sbin/stop-master.SH (kod = keluar, status = 0/kejayaan) Proses: 3339 execstart =/opt/spark/sbin/start-master.SH (CODE = Exited, Status = 0/Kejayaan) PID Utama: 3359 (Java) Tugas: 27 (Had: 12544) Memori: 219.3m cgroup: /sistem.Slice/Spark-Master.Perkhidmatan 3359/usr/lib/jvm/java-1.8.0-OpenJDK-1.8.0.181.B13-9.EL8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g org.Apache.percikan.menggunakan.tuan.Master -HOST [...] Jan 11 16:30:00 RHEL8Lab.Linuxconfig.Org Systemd [1]: Memulakan Apache Spark Master ... 11 Jan 16:30:00 RHEL8Lab.Linuxconfig.Org Start-Master.SH [3339]: Memulakan org.Apache.percikan.menggunakan.tuan.Master, Logging to/Opt/Spark/Logs/Spark-Spark-Org.Apache.percikan.menggunakan.tuan.Master-1 [...]
Baris terakhir juga menunjukkan logfile utama tuan, yang ada di
logdirektori di bawah direktori asas percikan,/memilih/percikan apiDalam kes kita. Dengan melihat ke dalam fail ini, kita harus melihat garis pada akhirnya sama dengan contoh di bawah:2019-01-11 14:45:28 Maklumat Master: 54-Saya telah dipilih sebagai pemimpin! Negeri Baru: Hidup
Kita juga harus mencari garis yang memberitahu kita di mana antara muka induk sedang mendengar:
2019-01-11 16:30:03 Maklumat Util: 54-Berjaya Memulakan Perkhidmatan 'Masterui' di Port 8080
Sekiranya kita menunjukkan penyemak imbas ke pelabuhan mesin tuan rumah
8080, Kita harus melihat halaman status tuan, tanpa pekerja yang dilampirkan pada masa ini.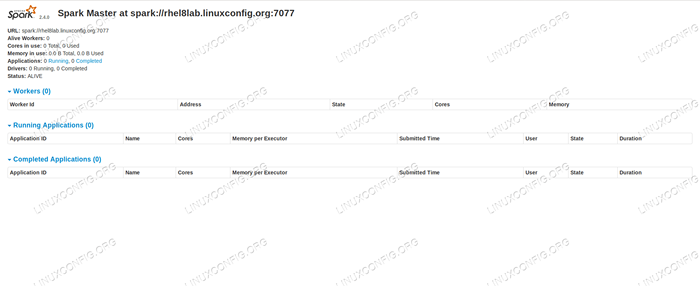 Halaman status induk percikan tanpa pekerja dilampirkan.
Halaman status induk percikan tanpa pekerja dilampirkan. Perhatikan garis URL di halaman status induk Spark. Ini adalah URL yang sama yang perlu kita gunakan untuk setiap fail unit hamba yang kita buat
Langkah 5.
Jika kami menerima mesej ralat "sambungan ditolak" dalam penyemak imbas, kami mungkin perlu membuka port pada firewall:# firewall-cmd --Zone = public --add-port = 8080/TCP-KejayaanPelat # Firewall-Cmd-Kejayaan Releed
- Tuan kita berjalan, kita akan melampirkan hamba kepadanya. Kami memulakan perkhidmatan hamba:
# Systemctl Mula Bercerai.perkhidmatan
- Kami dapat mengesahkan bahawa hamba kami berjalan dengan sistem:
# Systemctl Status Spark-Slave.Perkhidmatan Spark-Slave.Perkhidmatan - Apache Spark Slave Loaded: Loaded (/etc/Systemd/System/Spark -Slave.perkhidmatan; dilumpuhkan; Pratetap Vendor: dilumpuhkan) Aktif: Aktif (berjalan) sejak Jum 2019-01-11 16:31:41 CET; 1H 3min Ago Proses: 3515 EXECSTOP =/OPT/Spark/SBIN/Stop-Slave.SH (kod = keluar, status = 0/kejayaan) Proses: 3537 execstart =/opt/spark/sbin/start-hamba.sh spark: // rhel8lab.Linuxconfig.org: 7077 (kod = keluar, status = 0/kejayaan) PID Utama: 3554 (Java) Tugas: 26 (Had: 12544) Memori: 176.1m cgroup: /sistem.Slice/Spark-Slave.Perkhidmatan 3554/usr/lib/jvm/java-1.8.0-OpenJDK-1.8.0.181.B13-9.EL8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g org.Apache.percikan.menggunakan.pekerja.Pekerja [...] Jan 11 16:31:39 RHEL8Lab.Linuxconfig.Org Systemd [1]: Memulakan Hamba Apache Spark ... 11 Jan 16:31:39 RHEL8Lab.Linuxconfig.Org Start-Slave.SH [3537]: Memulakan org.Apache.percikan.menggunakan.pekerja.Pekerja, pembalakan ke/opt/percikan/log/percikan-spar [...]
Output ini juga menyediakan jalan ke logfile hamba (atau pekerja), yang akan berada dalam direktori yang sama, dengan "pekerja" dalam namanya. Dengan memeriksa fail ini, kita harus melihat sesuatu yang serupa dengan output di bawah:
2019-01-11 14:52:23 Maklumat Pekerja: 54-Menyambung ke Master Rhel8Lab.Linuxconfig.Org: 7077 ... 2019-01-11 14:52:23 Info Contexthandler: 781-Memulakan O.s.j.s.Servletcontexthandler@62059F4a /metrics/json, null, tersedia,@spark 2019-01-11 14:52:23 Info TransportClientFactory: 267-Berjaya dicipta sambungan ke RHEL8Lab.Linuxconfig.org/10.0.2.15: 7077 Selepas 58 ms (0 ms dibelanjakan dalam bootstraps) 2019-01-11 14:52:24 Maklumat Pekerja: 54-Berjaya berdaftar dengan Master Spark: // RHEL8Lab.Linuxconfig.Org: 7077
Ini menunjukkan bahawa pekerja berjaya dihubungkan dengan tuan. Dalam logfile yang sama ini kita akan mencari garis yang memberitahu kita URL pekerja sedang mendengar:
2019-01-11 14:52:23 Info WorkerWebui: 54-Bound WorkerWebui hingga 0.0.0.0, dan bermula di http: // rhel8lab.Linuxconfig.Org: 8081
Kami dapat menunjuk penyemak imbas kami ke halaman status pekerja, di mana tuannya disenaraikan.
 Halaman Status Pekerja Spark, disambungkan ke Master.
Halaman Status Pekerja Spark, disambungkan ke Master.
Di logfile tuan, garis pengesahan harus muncul:
2019-01-11 14:52:24 Maklumat Master: 54-Pekerja mendaftar 10.0.2.15: 40815 dengan 2 teras, 1024.0 MB RAM
Sekiranya kita memuatkan semula halaman status induk sekarang, pekerja harus muncul di sana juga, dengan pautan ke halaman status itu.
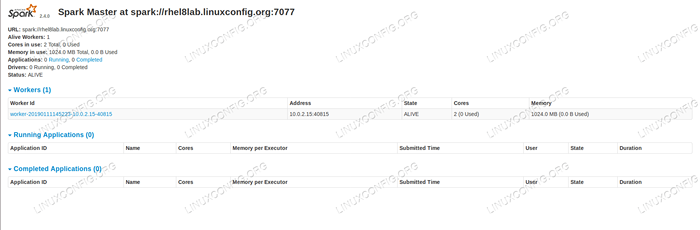 Halaman status induk percikan dengan satu pekerja dilampirkan.
Halaman status induk percikan dengan satu pekerja dilampirkan. Sumber -sumber ini mengesahkan bahawa kelompok kami dilampirkan dan bersedia untuk berfungsi.
- Untuk menjalankan tugas mudah pada kluster, kami melaksanakan salah satu contoh yang dihantar dengan pakej yang kami muat turun. Pertimbangkan fail teks mudah berikut
/opt/percikan/ujian.fail:
Salinanline1 word1 word2 word3 line2 word1 line3 word1 word2 word3 word4Kami akan melaksanakan
wordcount.pyContoh di atasnya yang akan mengira kejadian setiap perkataan dalam fail. Kita boleh menggunakanpercikanPengguna, tidakakarKeistimewaan diperlukan.$/opt/spark/bin/spark-submit/opt/spark/contoh/src/main/python/wordcount.py/opt/percikan/ujian.Fail 2019-01-11 15:56:57 Info SparkContext: 54-Permohonan yang dikemukakan: PythonwordCount 2019-01-11 15:56:57 Info SecurityManager: 54-Mengubah ACLS ke: Spark 2019-01-11 15:56: 57 Info SecurityManager: 54 - Menukar Ubahsuai ACLS ke: Spark [...]
Seperti yang dijalankan, output panjang disediakan. Dekat dengan akhir output, hasilnya ditunjukkan, kluster mengira maklumat yang diperlukan:
2019-01-11 15:57:05 Info Dagscheduler: 54-Job 0 Selesai: Kumpulkan di/opt/Spark/Contoh/Src/Main/Python/WordCount.PY: 40, mengambil 1.619928 s LINE3: 1 baris2: 1 baris1: 1 Word4: 1 Word1: 3 Word3: 2 Word2: 2 [...]
Dengan ini kita telah melihat Apache Spark dalam tindakan. Nod hamba tambahan boleh dipasang dan dilampirkan untuk skala kuasa pengkomputeran kluster kami.
Tutorial Linux Berkaitan:
- Cara Membuat Kluster Kubernet
- Pemasangan Oracle Java di Ubuntu 20.04 Focal Fossa Linux
- Perkara yang hendak dipasang di Ubuntu 20.04
- Cara Memasang Java di Manjaro Linux
- Linux: Pasang Java
- Cara memasang kubernet di ubuntu 20.04 Focal Fossa Linux
- Cara memasang Kubernet di Ubuntu 22.04 Jur -ubur Jammy ..
- Ubuntu 20.04 Hadoop
- Pengenalan kepada Automasi, Alat dan Teknik Linux
- Ubuntu 20.04 WordPress dengan pemasangan Apache