

Cara Memasang Cluster Node Single Hadoop (Pseudonode) pada CentOS 7

- 4101
- 320
- Jerome Quitzon
Hadoop adalah rangka kerja sumber terbuka yang digunakan secara meluas untuk menangani Data besar. Kebanyakannya BigData/Data Analytics projek sedang dibina di atas Hadoop Eco-System. Ia terdiri daripada dua lapisan, satu adalah untuk Menyimpan data dan yang lain adalah untuk Data pemprosesan.
Penyimpanan akan dijaga oleh sistem failnya sendiri yang dipanggil HDFS (Hadoop diedarkan sistem fail) dan Pemprosesan akan dijaga oleh Benang (Satu lagi perunding sumber). MapReduce adalah enjin pemprosesan lalai dari Hadoop Eco-System.
Artikel ini menerangkan proses untuk memasang Pseudonode pemasangan Hadoop, di mana semua Daemons (JVMS) akan berjalan Nod tunggal Kelompok pada Centos 7.
Ini terutamanya untuk pemula untuk belajar Hadoop. Dalam masa nyata, Hadoop akan dipasang sebagai kluster multinode di mana data akan diedarkan di antara pelayan sebagai blok dan pekerjaan akan dilaksanakan secara selari.
Prasyarat
- Pemasangan minimum pelayan CentOS 7.
- Java v1.8 pelepasan.
- Hadoop 2.X Stable Release.
Pada halaman ini
- Cara Memasang Java di CentOS 7
- Sediakan log masuk tanpa kata laluan pada CentOS 7
- Cara memasang nod tunggal Hadoop di CentOS 7
- Cara Mengkonfigurasi Hadoop di CentOS 7
- Memformat sistem fail HDFS melalui namenode
Memasang Java di CentOS 7
1. Hadoop adalah sistem eko yang terdiri daripada Java. Kita perlu Java dipasang di sistem kami untuk memasang Hadoop.
# yum pasang java-1.8.0-OpenJDK
2. Seterusnya, sahkan versi yang dipasang Java pada sistem.
# java -versi
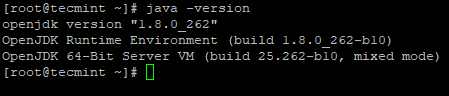 sahkan versi Java
sahkan versi Java Konfigurasikan log masuk tanpa kata laluan pada CentOS 7
Kami perlu dikonfigurasi SSH di mesin kami, Hadoop akan menguruskan nod dengan penggunaan SSH. Penggunaan nod induk SSH sambungan untuk menyambungkan nod hamba dan melakukan operasi seperti Start and Stop.
Kita perlu menyediakan ssh yang kurang kata laluan supaya tuan dapat berkomunikasi dengan budak menggunakan ssh tanpa kata laluan. Jika tidak untuk setiap pertubuhan sambungan, perlu memasukkan kata laluan.
Dalam nod tunggal ini, Tuan perkhidmatan (Namenode, Namenode sekunder & Pengurus Sumber) dan Hamba perkhidmatan (DataNode & Nodemanager) akan berjalan sebagai berasingan JVMS. Walaupun ia adalah node singe, kita perlu mempunyai ssh yang kurang kata laluan untuk membuat Tuan Untuk berkomunikasi Hamba tanpa pengesahan.
3. Sediakan log masuk SSH yang kurang kata laluan menggunakan arahan berikut di pelayan.
# ssh-keygen # ssh-copy-id -i localhost
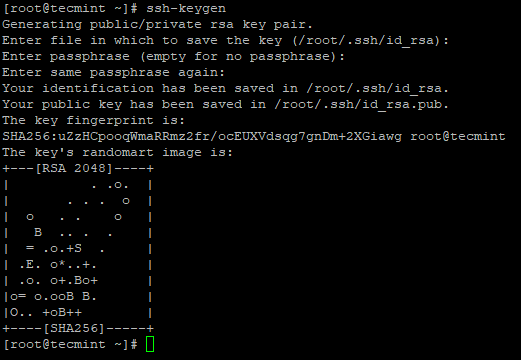 Buat keygen SSH di CentOS 7
Buat keygen SSH di CentOS 7 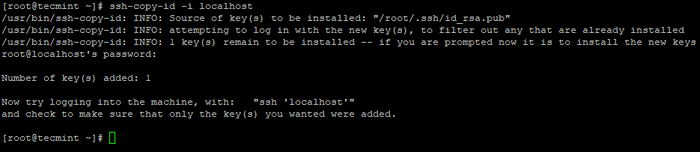 Salin Kunci SSH ke CentOS 7
Salin Kunci SSH ke CentOS 7 4. Setelah anda mengkonfigurasi log masuk SSH tanpa kata laluan, cuba log masuk lagi, anda akan disambungkan tanpa kata laluan.
# ssh localhost
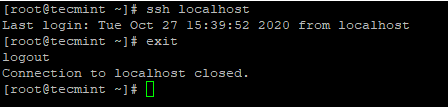 Log masuk tanpa kata laluan SSH ke CentOS 7
Log masuk tanpa kata laluan SSH ke CentOS 7 Memasang Hadoop di CentOS 7
5. Pergi ke laman web Apache Hadoop dan muat turun pelepasan stabil Hadoop menggunakan perintah wget berikut.
# wget https: // arkib.Apache.Org/Dist/Hadoop/Core/Hadoop-2.10.1/Hadoop-2.10.1.tar.GZ # TAR XVPZF HADOOP-2.10.1.tar.Gz
6. Seterusnya, tambahkan Hadoop Pembolehubah persekitaran dalam ~/.Bashrc fail seperti yang ditunjukkan.
HADOOP_PREFIX =/root/hadoop-2.10.1 Path = $ Path: $ Hadoop_Prefix/Bin Path Export Java_Home Hadoop_prefix
7. Setelah menambahkan pembolehubah persekitaran ke ~/.Bashrc Fail, sumber fail dan sahkan Hadoop dengan menjalankan arahan berikut.
# sumber ~/.BASHRC # CD $ HADOOP_PREFIX # bin/Hadoop Versi
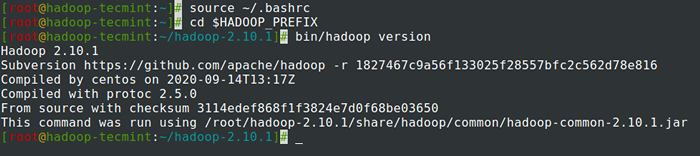 Semak versi Hadoop di CentOS 7
Semak versi Hadoop di CentOS 7 Mengkonfigurasi Hadoop di CentOS 7
Kami perlu mengkonfigurasi fail konfigurasi di bawah Hadoop agar sesuai dengan mesin anda. Dalam Hadoop, Setiap perkhidmatan mempunyai nombor port sendiri dan direktori sendiri untuk menyimpan data.
- Fail Konfigurasi Hadoop - Laman Teras.XML, tapak HDFS.XML, MAPRED-SITE.XML & Benang-tapak.XML
8. Pertama, kita perlu mengemas kini Java_home dan Hadoop jalan di Hadoop-ENV.sh fail seperti yang ditunjukkan.
# CD $ Hadoop_Prefix/etc/Hadoop # VI Hadoop-ENV.sh
Masukkan baris berikut pada permulaan fail.
Eksport java_home =/usr/lib/jvm/java-1.8.0/JRE Export Hadoop_Prefix =/root/Hadoop-2.10.1
9. Seterusnya, ubah suai tapak teras.XML fail.
# CD $ HADOOP_PREFIX/etc/Hadoop # VI Laman Teras.XML
Tampal berikut tag seperti yang ditunjukkan.
fs.defaultfs hdfs: // localhost: 9000
10. Buat di bawah di bawah Tecmint direktori rumah pengguna, yang akan digunakan untuk Nn dan Dn penyimpanan.
# mkdir -p/home/tecmint/hdata/ # mkdir -p/home/tecmint/hdata/data # mkdir -p/home/tecmint/hdata/nama
10. Seterusnya, ubah suai tapak HDFS.XML fail.
# CD $ Hadoop_Prefix/etc/Hadoop # VI HDFS-Site.XML
Tampal berikut tag seperti yang ditunjukkan.
DFS.Replikasi 1 DFS.namenode.nama.dir/rumah/tecmint/hdata/nama dfs .DataNode.data.Dir Home/Tecmint/HData/Data
11. Sekali lagi, ubah suai tapak peta.XML fail.
# CD $ HADOOP_PREFIX/etc/Hadoop # CP MAPRED-SITE.XML.Template Mapred-site.XML # VI MAPRED-SITE.XML
Tampal berikut tag seperti yang ditunjukkan.
MapReduce.Rangka Kerja.Nama benang
12. Terakhir, ubah suai tapak benang.XML fail.
# CD $ Hadoop_Prefix/etc/Hadoop # VI Benang-tapak.XML
Tampal berikut tag seperti yang ditunjukkan.
Benang.Nodemanager.Aux-Services MapReduce_Shuffle
Memformat sistem fail HDFS melalui namenode
13. Sebelum memulakan Kelompok, kita perlu memformat Hadoop nn dalam sistem tempatan kami di mana ia telah dipasang. Biasanya, ia akan dilakukan pada peringkat awal sebelum memulakan kluster pada kali pertama.
Memformat Nn akan menyebabkan kehilangan data di nn metastore, jadi kita harus lebih berhati -hati, kita tidak boleh memformat Nn sementara kelompok berjalan melainkan jika diperlukan dengan sengaja.
# CD $ Hadoop_prefix # bin/Hadoop Namenode -Format
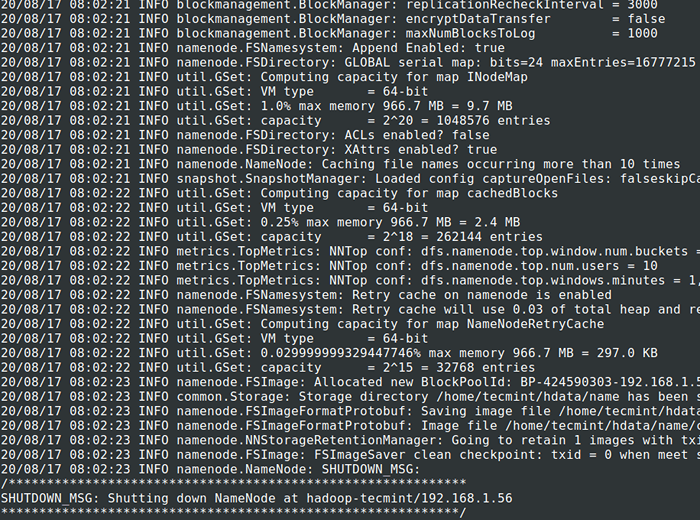 Format HDFS Filesystem
Format HDFS Filesystem 14. Mula Namenode Daemon dan DataNode Daemon: (Port 50070).
# CD $ HADOOP_PREFIX # SBIN/START-DFS.sh
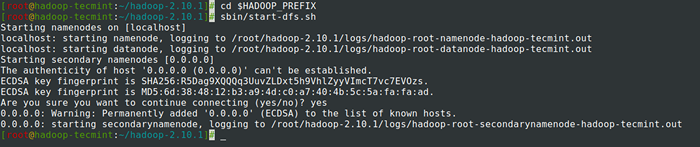 Mulakan Namenode dan Daemon DaTanode
Mulakan Namenode dan Daemon DaTanode 15. Mula ResourceManager Daemon dan Nodemanager Daemon: (Port 8088).
# sbin/start-yarn.sh
 Mulakan ResourceManager dan Nodemanager Daemon
Mulakan ResourceManager dan Nodemanager Daemon 16. Untuk menghentikan semua perkhidmatan.
# sbin/stop-dfs.SH # SBIN/STOP-DFS.sh
Ringkasan
Ringkasan
Dalam artikel ini, kami telah melalui proses langkah demi langkah untuk disediakan Hadoop Pseudonode (Nod tunggal) Kelompok. Sekiranya anda mempunyai pengetahuan asas mengenai Linux dan ikuti langkah -langkah ini, kelompok akan naik dalam 40 minit.
Ini sangat berguna bagi pemula untuk mula belajar dan berlatih Hadoop atau versi vanila ini Hadoop boleh digunakan untuk tujuan pembangunan. Sekiranya kita ingin mempunyai kelompok masa nyata, sama ada kita memerlukan sekurang-kurangnya 3 pelayan fizikal di tangan atau perlu menyediakan awan kerana mempunyai beberapa pelayan.
- « Menyediakan prasyarat Hadoop dan pengerasan keselamatan - Bahagian 2
- Apa itu MongoDB? Bagaimana MongoDB berfungsi? »