

Cara Memasang Hadoop di Ubuntu 18.04 Bionic Beaver Linux
- 4096
- 520
- Daryl Wilderman
Apache Hadoop adalah kerangka sumber terbuka yang digunakan untuk penyimpanan yang diedarkan serta pemprosesan data besar mengenai kelompok komputer yang berjalan pada hardwares komoditi. Hadoop menyimpan data dalam sistem fail diedarkan Hadoop (HDFS) dan pemprosesan data ini dilakukan menggunakan MapReduce. Benang menyediakan API untuk meminta dan memperuntukkan sumber dalam kumpulan Hadoop.
Rangka kerja Apache Hadoop terdiri daripada modul berikut:
- Hadoop biasa
- Hadoop diedarkan Sistem Fail (HDFS)
- Benang
- MapReduce
Artikel ini menerangkan cara memasang Hadoop Versi 2 di Ubuntu 18.04. Kami akan memasang HDFS (Namenode dan Datanode), benang, MapReduce pada kluster nod tunggal dalam mod diedarkan pseudo yang diedarkan simulasi pada mesin tunggal. Setiap Daemon Hadoop seperti HDFS, Benang, MapReduce dll. akan dijalankan sebagai proses Java yang berasingan/individu.
Dalam tutorial ini anda akan belajar:
- Cara Menambah Pengguna untuk Persekitaran Hadoop
- Cara memasang dan mengkonfigurasi jdk oracle
- Cara Mengkonfigurasi SSH Tanpa Kata Laluan
- Cara Memasang Hadoop dan Konfigurasi Fail XML Berkaitan yang Diperlukan
- Cara Memulakan Kluster Hadoop
- Cara Mengakses UI Web Namenode dan ResourceManager
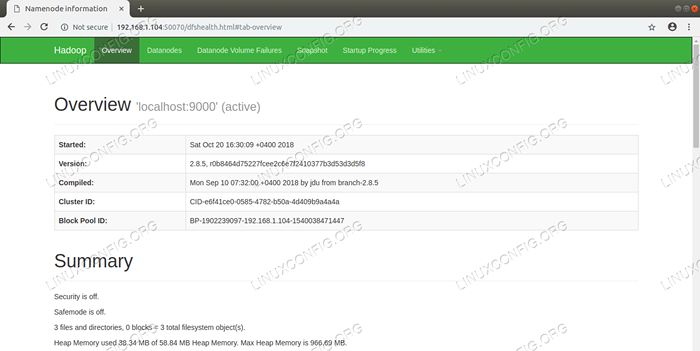
Antara muka pengguna web namenode. Keperluan perisian dan konvensyen yang digunakan
| Kategori | Keperluan, konvensyen atau versi perisian yang digunakan |
|---|---|
| Sistem | Ubuntu 18.04 |
| Perisian | Hadoop 2.8.5, Oracle JDK 1.8 |
| Yang lain | Akses istimewa ke sistem linux anda sebagai akar atau melalui sudo perintah. |
| Konvensyen | # - Memerlukan arahan Linux yang diberikan untuk dilaksanakan dengan keistimewaan akar sama ada secara langsung sebagai pengguna root atau dengan menggunakan sudo perintah$ - Memerlukan arahan Linux yang diberikan sebagai pengguna yang tidak layak |
Versi lain dalam tutorial ini
Ubuntu 20.04 (Focal Fossa)
Tambahkan Pengguna untuk Persekitaran Hadoop
Buat pengguna dan kumpulan baru menggunakan arahan:
# tambah pengguna
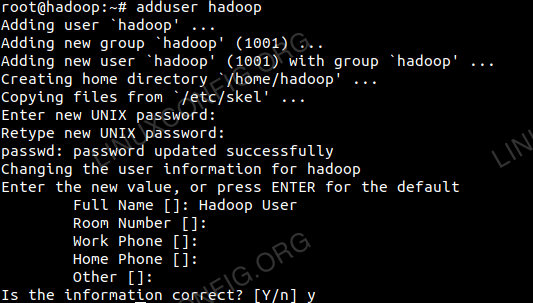 Tambahkan pengguna baru untuk Hadoop.
Tambahkan pengguna baru untuk Hadoop.
Pasang dan konfigurasikan Oracle JDK
Muat turun dan ekstrak Arkib Java di bawah /Memilih direktori.
# CD /OPT # TAR -XZVF JDK-8U192-LINUX-X64.tar.Gz
atau
$ tar -XZVF JDK-8U192-LINUX-X64.tar.gz -c /opt
Untuk menetapkan JDK 1.8 Kemas kini 192 Sebagai JVM lalai kami akan menggunakan arahan berikut:
# kemas kini-alternatif-pemasangan/usr/bin/java java/opt/jdk1.8.0_192/bin/java 100 # update-alternatives-Install/usr/bin/javac javac/opt/jdk1.8.0_192/bin/javac 100
Selepas pemasangan untuk mengesahkan Java telah berjaya dikonfigurasikan, jalankan arahan berikut:
# Kemas kini-Alternatif-Jawa Java # Update-Alternatif-Javac Javac
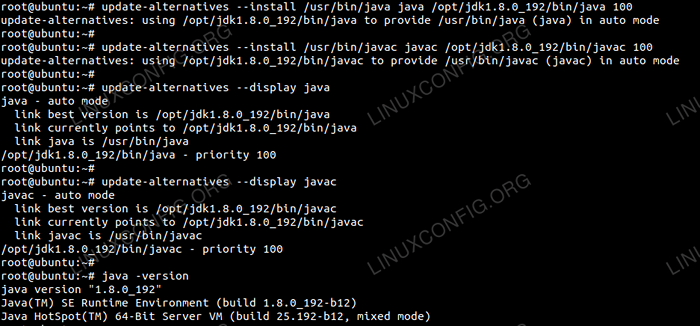 Pemasangan & Konfigurasi OracleJDK.
Pemasangan & Konfigurasi OracleJDK. Konfigurasikan ssh tanpa kata laluan
Pasang pelayan SSH terbuka dan buka klien SSH dengan arahan:
# sudo apt-get pemasangan openssh-server openssh-client
Menjana pasangan utama awam dan swasta dengan arahan berikut. Terminal akan meminta memasukkan nama fail. Tekan Masukkan dan teruskan. Setelah itu menyalin borang kunci awam id_rsa.pub ke diberi kuasa_keys.
$ ssh -keygen -t rsa $ Cat ~/.SSH/ID_RSA.pub >> ~/.SSH/Authorized_keys
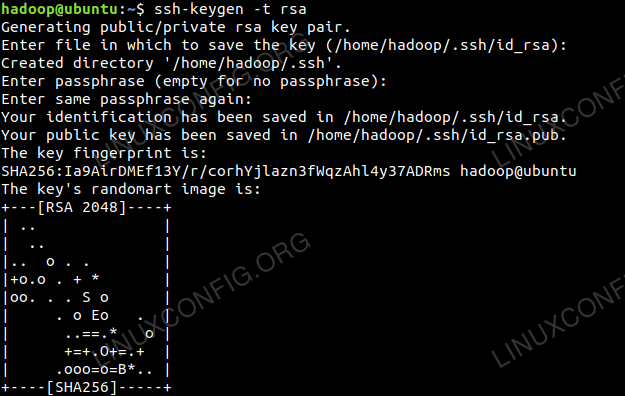 Konfigurasi SSH Kata Laluan.
Konfigurasi SSH Kata Laluan.
Sahkan konfigurasi SSH yang kurang kata laluan dengan arahan:
$ ssh localhost
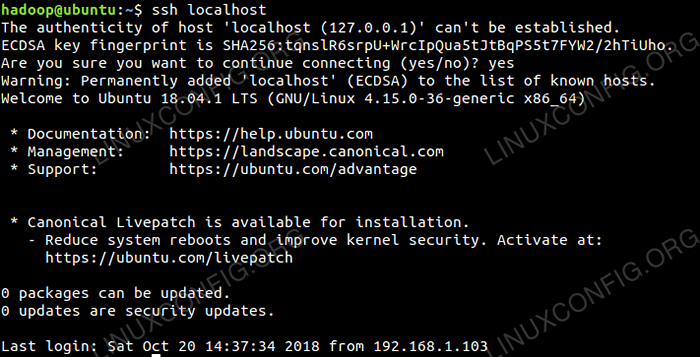 Pemeriksaan SSH tanpa kata laluan.
Pemeriksaan SSH tanpa kata laluan.
Pasang Hadoop dan konfigurasikan fail XML yang berkaitan
Muat turun dan ekstrak Hadoop 2.8.5 dari laman web rasmi Apache.
# tar -xzvf Hadoop -2.8.5.tar.Gz
Menyediakan pembolehubah persekitaran
Edit Bashrc Bagi pengguna Hadoop melalui menyediakan pembolehubah persekitaran Hadoop berikut:
Eksport HADOOP_HOME =/rumah/Hadoop/Hadoop-2.8.5 eksport hadoop_install = $ Hadoop_Home Export Hadoop_Mapred_Home = $ Hadoop_Home Export Hadoop_Common_Home = $ Hadoop_Home Export Hadoop_Hdfs_Home = $ Hadoop_Home Export Yarn_Home Eksport Hadoop_Opts = "-Djava.Perpustakaan.Path = $ hadoop_home/lib/asli " Sumber .Bashrc dalam sesi log masuk semasa.
$ sumber ~/.Bashrc
Edit Hadoop-ENV.sh fail yang ada /etc/Hadoop Di dalam direktori pemasangan Hadoop dan buat perubahan berikut dan periksa jika anda ingin menukar konfigurasi lain.
Eksport java_home =/opt/jdk1.8.0_192 Eksport HADOOP_CONF_DIR = $ HADOOP_CONF_DIR:-"/Home/Hadoop/Hadoop-2.8.5/etc/Hadoop " 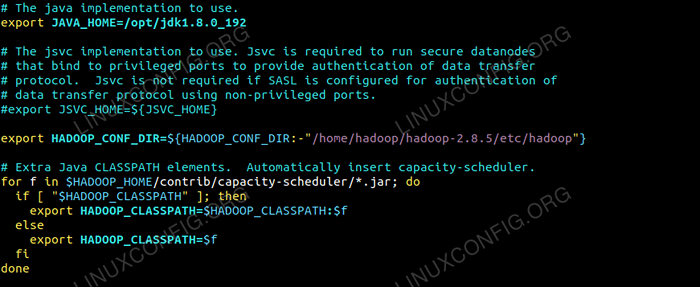 Perubahan dalam Hadoop-ENV.fail sh.
Perubahan dalam Hadoop-ENV.fail sh. Perubahan konfigurasi di tapak teras.Fail XML
Edit tapak teras.XML dengan vim atau anda boleh menggunakan mana -mana editor. Fail tersebut berada di bawah /etc/Hadoop dalam Hadoop direktori rumah dan tambahkan penyertaan berikut.
fs.defaultfs HDFS: // localhost: 9000 Hadoop.TMP.dir /rumah/Hadoop/Hadooptmpdata Di samping itu, buat direktori di bawah Hadoop folder rumah.
$ mkdir hadooptmpdata
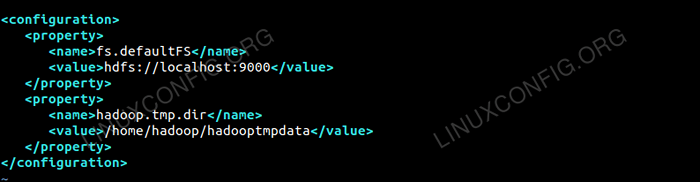 Konfigurasi untuk tapak teras.Fail XML.
Konfigurasi untuk tapak teras.Fail XML. Perubahan konfigurasi di tapak HDFS.Fail XML
Edit tapak HDFS.XML yang terdapat di bawah lokasi yang sama i.e /etc/Hadoop dalam Hadoop direktori pemasangan dan buat Namenode/Datanode direktori di bawah Hadoop direktori rumah pengguna.
$ mkdir -p hdfs/namenode $ mkdir -p hdfs/daTanode
DFS.replikasi 1 DFS.nama.dir Fail: /// Home/Hadoop/HDFS/Namenode DFS.data.dir Fail: /// Home/Hadoop/HDFS/Datanode 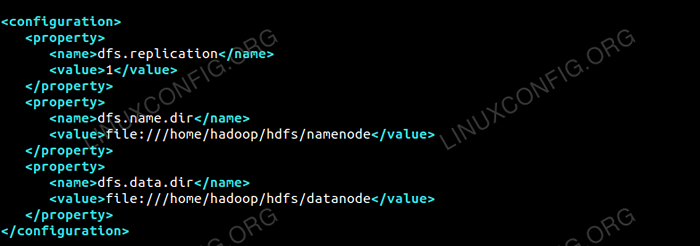 Konfigurasi untuk tapak HDFS.Fail XML.
Konfigurasi untuk tapak HDFS.Fail XML. Perubahan Konfigurasi di Laman Mapred.Fail XML
Salin tapak peta.XML dari tapak peta.XML.templat menggunakan cp perintah dan kemudian edit tapak peta.XML diletakkan di /etc/Hadoop di bawah Hadoop Direktori Instillation dengan perubahan berikut.
$ cp mapred-site.XML.Template Mapred-site.XML
 Membuat tapak Mapred baru.Fail XML.
Membuat tapak Mapred baru.Fail XML. MapReduce.Rangka Kerja.nama Benang  Konfigurasi untuk tapak Mapred.Fail XML.
Konfigurasi untuk tapak Mapred.Fail XML. Perubahan konfigurasi di tapak benang.Fail XML
Edit tapak benang.XML dengan penyertaan berikut.
MapReduceyarn.Nodemanager.Aux-Services mapreduce_shuffle  Konfigurasi untuk tapak benang.Fail XML.
Konfigurasi untuk tapak benang.Fail XML. Memulakan kelompok Hadoop
Format namenode sebelum menggunakannya untuk kali pertama. Sebagai pengguna HDFS menjalankan arahan di bawah untuk memformat namenode.
$ hdfs namenode -format
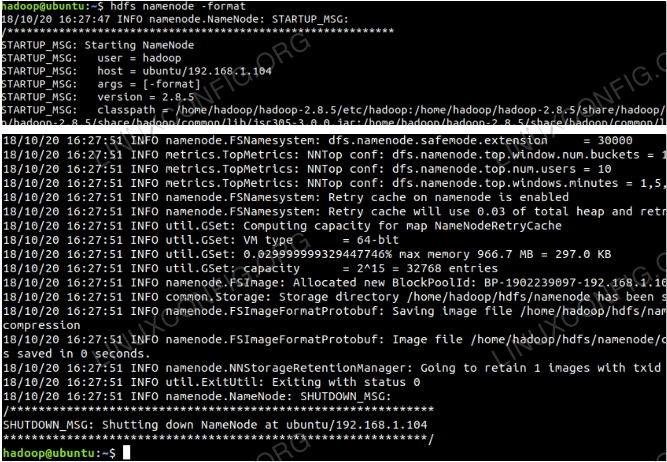 Format namenode.
Format namenode.
Setelah namenode telah diformat maka mulakan HDF menggunakan start-dfs.sh Skrip.
 Memulakan skrip permulaan DFS untuk memulakan HDFS.
Memulakan skrip permulaan DFS untuk memulakan HDFS.
Untuk memulakan perkhidmatan benang, anda perlu melaksanakan skrip permulaan benang i.e. Start-Yarn.sh
 Memulakan Skrip Permulaan Benang Untuk Memulakan Benang.
Memulakan Skrip Permulaan Benang Untuk Memulakan Benang. Untuk mengesahkan semua perkhidmatan Hadoop/daemon dimulakan dengan jayanya, anda boleh menggunakan JPS perintah.
/opt/jdk1.8.0_192/bin/jps 20035 Secondarynamenode 19782 Datanode 21671 JPS 20343 Nodemanager 19625 Namenode 20187 ResourceManager  Output Hadoop Daemons dari Perintah JPS.
Output Hadoop Daemons dari Perintah JPS.
Sekarang kita boleh menyemak versi Hadoop semasa yang boleh anda gunakan di bawah arahan:
versi $ Hadoop
atau
$ HDFS versi
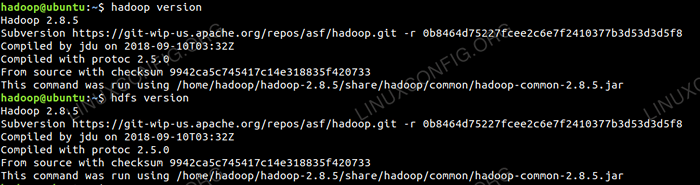 Semak versi Hadoop.
Semak versi Hadoop.
Antara muka baris arahan HDFS
Untuk mengakses HDFS dan buat beberapa direktori atas DFS anda boleh menggunakan HDFS CLI.
$ hdfs dfs -mkdir /test $ hdfs dfs -mkdir /hadooponubuntu $ hdfs dfs -ls /
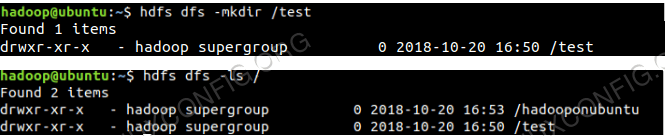 Penciptaan Direktori HDFS Menggunakan HDFS CLI.
Penciptaan Direktori HDFS Menggunakan HDFS CLI.
Akses namenode dan benang dari penyemak imbas
Anda boleh mengakses kedua -dua UI Web untuk Namenode dan Pengurus Sumber Benang melalui mana -mana pelayar seperti Google Chrome/Mozilla Firefox.
Namenode Web UI - http: //: 50070
Antara muka pengguna web namenode. 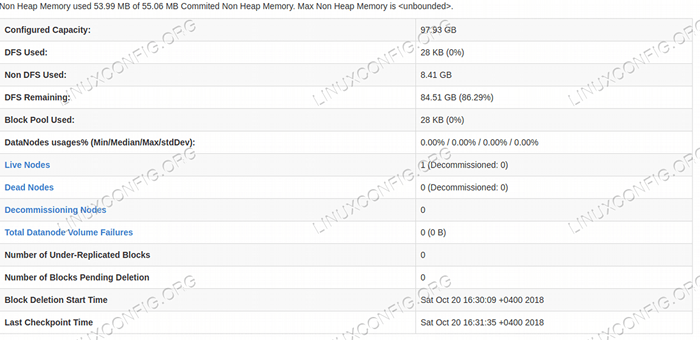 Butiran HDFS dari Antara Muka Pengguna Web Namenode.
Butiran HDFS dari Antara Muka Pengguna Web Namenode. 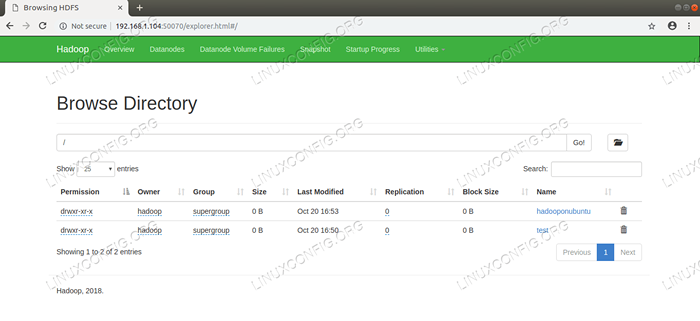 Layari Direktori HDFS Melalui Antara Muka Pengguna Web Namenode.
Layari Direktori HDFS Melalui Antara Muka Pengguna Web Namenode. Antara muka web Pengurus Sumber Benang (RM) akan memaparkan semua pekerjaan yang sedang berjalan pada cluster Hadoop semasa.
UI Web Pengurus Sumber - http: //: 8088
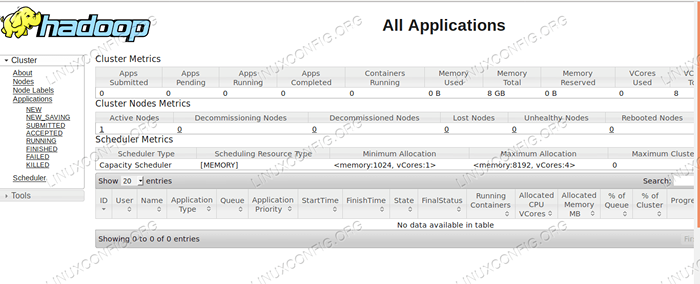 Antara Muka Pengguna Web Pengurus Sumber.
Antara Muka Pengguna Web Pengurus Sumber. Kesimpulan
Dunia mengubah cara ia beroperasi pada masa ini dan data besar memainkan peranan utama dalam fasa ini. Hadoop adalah rangka kerja yang memudahkan kita semasa bekerja pada set data yang besar. Terdapat peningkatan di semua bidang. Masa depan menarik.
Tutorial Linux Berkaitan:
- Ubuntu 20.04 Hadoop
- Perkara yang hendak dipasang di Ubuntu 20.04
- Cara Membuat Kluster Kubernet
- Cara memasang kubernet di ubuntu 20.04 Focal Fossa Linux
- Perkara yang perlu dilakukan setelah memasang ubuntu 20.04 Focal Fossa Linux
- Cara memasang Kubernet di Ubuntu 22.04 Jur -ubur Jammy ..
- Perkara yang perlu dipasang di Ubuntu 22.04
- Cara Bekerja Dengan API Rest WooCommerce dengan Python
- Cara Mengurus Kluster Kubernet dengan Kubectl
- Pengenalan kepada Automasi, Alat dan Teknik Linux
- « Cara Memasang Android Studio di Manjaro 18 Linux
- Cara Memasang Google Chrome di Manjaro 18 Linux »