

Cara Memasang Kluster Elasticsearch (Multi Node) di Centos/Rhel, Ubuntu & Debian

- 1488
- 122
- Dana Hammes
Elasticsearch adalah sumber terbuka yang fleksibel dan kuat, carian masa nyata dan enjin analitik yang diedarkan. Menggunakan set API yang mudah, ia memberikan keupayaan untuk carian teks penuh. Carian elastik tersedia secara bebas di bawah lesen Apache 2, yang memberikan kelonggaran yang paling banyak.
Artikel ini akan membantu anda untuk mengkonfigurasi Elasticsearch Multi Node Cluster di Centos, Rhel, Ubuntu dan Debian Systems. Di Elasticsearch Multi Node Cluster hanya mengkonfigurasi pelbagai kelompok nod tunggal dengan nama kluster yang sama dalam rangkaian yang sama.
Rangkaian Scenerio
Kami mempunyai tiga pelayan dengan nama IPS dan tuan rumah berikut. Semua pelayan berjalan di LAN yang sama dan mempunyai akses penuh ke pelayan masing -masing menggunakan IP dan nama host kedua -duanya.
192.168.10.101 node_1 192.168.10.102 node_2 192.168.10.103 node_3
Sahkan Java (semua nod)
Java adalah keperluan utama untuk memasang elasticsearch. Oleh itu, pastikan anda memasang Java pada semua nod.
# Java -versi Java Versi "1.8.0_31 "Java (TM) SE Runtime Environment (Membina 1.8.0_31-b13) Java Hotspot (TM) 64-bit Server VM (Bina 25.31-b07, mod campuran)
Sekiranya anda tidak memasang Java pada mana -mana sistem nod, gunakan salah satu pautan berikut untuk memasangnya terlebih dahulu.
Pasang Java 8 di CentOS/RHEL 7/6/5
Pasang Java 8 di Ubuntu
Muat turun Elasticsearch (semua nod)
Sekarang muat turun arkib Elasticsearch terkini di semua sistem nod dari halaman muat turun rasminya. Pada masa kemas kini terakhir artikel ini Elasticsearch 1.4.Versi 2 adalah versi terkini yang boleh dimuat turun. Gunakan arahan berikut untuk memuat turun Elasticsearch 1.4.2.
$ wget https: // muat turun.Elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.2.tar.Gz
Sekarang ekstrak elasticsearch pada semua sistem nod.
$ tar xzf elasticsearch-1.4.2.tar.Gz
Konfigurasi Elasticsearch
Sekarang kita perlu menyediakan Elasticsearch pada semua sistem nod. Elasticsearch menggunakan "elasticsearch" sebagai nama cluster lalai. Kami mengesyorkan untuk mengubahnya mengikut perbualan penamaan anda.
$ mv elasticsearch-1.4.2/usr/share/elasticsearch $ cd/usr/share/elasticsearch
Untuk menukar kluster bernama Edit Config/Elasticsearch.yml fail dalam setiap nod dan kemas kini nilai berikut. Nama nod dihasilkan secara dinamik, tetapi untuk menyimpan nama mesra pengguna tetap mengubahnya juga.
Pada node_1
Edit Konfigurasi Kluster Elasticsearch di Node_1 (192.168.10.101) Sistem.
$ vim config/elasticsearch.yml
kelompok.Nama: Tecadmincluster Node.Nama: "Node_1"
Pada node_2
Edit Konfigurasi Kluster Elasticsearch pada Node_2 (192.168.10.102) sistem.
$ vim config/elasticsearch.yml
kelompok.Nama: Tecadmincluster Node.Nama: "node_2"
Pada node_3
Edit Konfigurasi Kluster Elasticsearch di Node_3 (192.168.10.103) sistem.
$ vim config/elasticsearch.yml
kelompok.Nama: Tecadmincluster Node.Nama: "node_3"
Pasang plugin Elasticsearch-Head (semua nod)
Elasticsearch-Head adalah hujung depan web untuk melayari dan berinteraksi dengan cluster carian elastik. Gunakan arahan berikut untuk memasang plugin ini pada semua sistem nod.
$ bin/plugin-memasang MOBZ/ELASTICSEARK-HEAD
Memulakan Kluster Elasticsearch (semua nod)
Oleh kerana persediaan kluster Elasticsearch telah selesai. Biarkan Mula Elasticsearch Cluster menggunakan arahan berikut pada semua nod.
$ ./bin/elasticsearch &
Secara lalai elasticserch dengar di port 9200 dan 9300. Jadi sambungkan ke Node_1 Di port 9200 seperti url berikut, anda akan melihat ketiga -tiga nod dalam kelompok anda.
http: // node_1: 9200/_plugin/kepala/
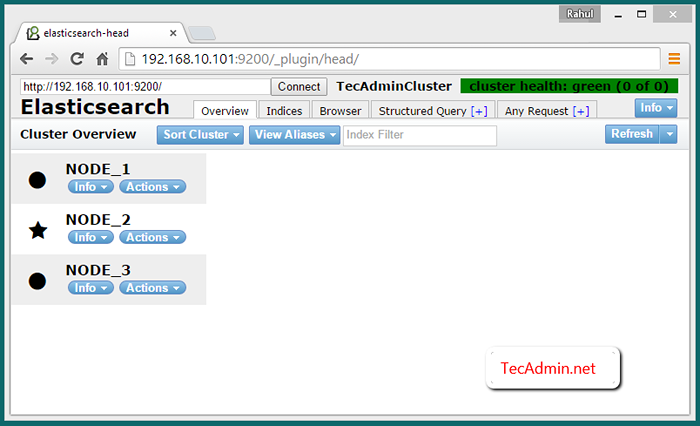
Sahkan kelompok pelbagai nod
Untuk mengesahkan bahawa kluster berfungsi dengan baik. Masukkan beberapa data dalam satu nod dan jika data yang sama tersedia dalam nod lain, ini bermakna kluster berfungsi dengan baik.
Masukkan data pada node_1
Untuk mengesahkan kluster buat baldi di Node_1 dan tambahkan beberapa data.
$ curl -xput http: // node_1: 9200/mybucket $ curl -xput 'http: // node_1: 9200/mybucket/user/rahul' -d '"name": "rahul kumar"'
$ curl -xput 'http: // node_1: 9200/mybucket/post/1' -d '"user": "rahul", "postdate": "01-16-2015", "body": "tambah data dalam kluster elasticsearch "," tajuk ":" Ujian kluster Elasticsearch " '
Cari data pada semua nod
Sekarang cari data yang sama dari Node_2 dan Node_3 dan periksa sama ada data yang sama direplikasi pada nod lain cluster. Seperti perintah di atas, kami telah membuat pengguna bernama Rahul dan menambah beberapa data di sana. Oleh itu, gunakan arahan berikut untuk mencari data yang berkaitan dengan pengguna Rahul.
$ curl 'http: // node_1: 9200/mybucket/post/_search?Q = Pengguna: Rahul & Pretty = True '$ curl' http: // node_2: 9200/mybucket/post/_search?Q = Pengguna: Rahul & Pretty = True '$ curl' http: // node_3: 9200/mybucket/post/_search?Q = Pengguna: Rahul & Pretty = True '
dan anda akan mendapat hasil seperti di bawah untuk semua arahan di atas.
"mengambil": 69, "timed_out": false, "_shards": "total": 5, "berjaya": 5, "gagal": 0, "hits": "total": 1, "max_score ": 1.0, "hits": ["_index": "mybucket", "_type": "pos", "_id": "1", "_score": 1.0, "_source": "user": "rahul", "postdate": "01-16-2015", "body": "tambah data dalam kluster elasticsearch", "tajuk": "Ujian kluster Elasticsearch" ]
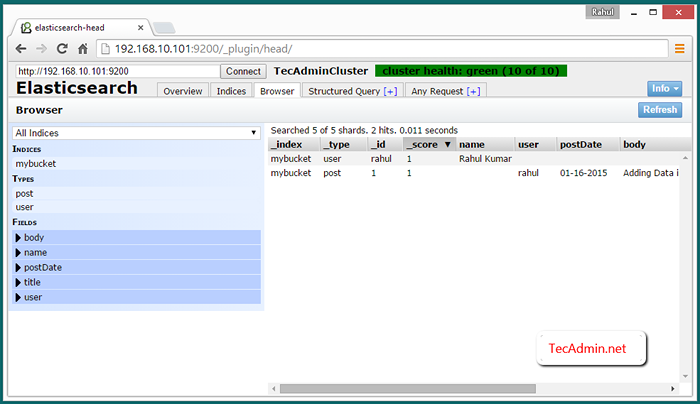
Lihat data kluster pada penyemak imbas web
Untuk melihat data mengenai akses kluster elasticsearch plugin elasticsearch-head menggunakan salah satu IP kluster di bawah URL. Kemudian klik pada Penyemak imbas tab.
http: // node_1: 9200/_plugin/kepala/
- « Cara Menggunakan Perintah SystemCtl untuk Mengurus Perkhidmatan Sistem
- Menambah Epel Repositori Tambahan dan Remi pada sistem berasaskan RHEL »