

Cara memasang Apache Hadoop di Ubuntu 22.04

- 1928
- 226
- Clay Weber
Memahami data yang tidak berstruktur dan menganalisis sejumlah besar data adalah permainan bola yang berbeza hari ini. Oleh itu, perniagaan telah menggunakan Apache Hadoop dan teknologi lain yang berkaitan untuk menguruskan data mereka yang tidak berstruktur dengan lebih cekap. Bukan hanya perniagaan tetapi juga individu menggunakan Apache Hadoop untuk pelbagai tujuan, seperti menganalisis dataset besar atau membuat laman web yang dapat memproses pertanyaan pengguna. Walau bagaimanapun, memasang Apache Hadoop di Ubuntu mungkin kelihatan seperti tugas yang sukar bagi pengguna yang baru ke dunia pelayan Linux. Nasib baik, anda tidak perlu menjadi pentadbir sistem yang berpengalaman untuk memasang Apache Hadoop di Ubuntu.
Panduan pemasangan langkah demi langkah berikut akan membawa anda melalui keseluruhan proses daripada memuat turun perisian untuk mengkonfigurasi pelayan dengan mudah. Dalam artikel ini, kami akan menerangkan cara memasang Apache Hadoop di Ubuntu 22.04 Sistem LTS. Ini juga boleh digunakan untuk versi Ubuntu yang lain.
Langkah 1: Pasang Kit Pembangunan Java
Java adalah komponen yang diperlukan dari Apache Hadoop, jadi anda perlu memuat turun dan memasang kit pembangunan Java pada semua nod di rangkaian anda di mana Hadoop akan dipasang. Anda boleh memuat turun JRE atau JDK. Sekiranya anda hanya ingin menjalankan Hadoop, maka JRE cukup, tetapi jika anda ingin membuat aplikasi yang berjalan di Hadoop, maka anda perlu memasang JDK. Versi terbaru Java yang menyokong Hadoop ialah Java 8 dan 11. Anda boleh mengesahkannya di laman web Apache dan memuat turun versi Java yang relevan bergantung pada OS anda.
- Repositori Ubuntu lalai mengandungi Java 8 dan Java 11 kedua -duanya. Gunakan arahan berikut untuk memasangnya.
Sudo Apt Update & Sudo Apt Pasang OpenJDK-11-JDK - Sebaik sahaja anda berjaya memasangnya, periksa versi Java semasa:
java -versi Semak versi Java
Semak versi Java - Anda boleh menemui lokasi direktori java_home dengan menjalankan arahan berikut. Yang diperlukan terkini dalam artikel ini.
Dirname $ (dirname $ (readlink -f $ (yang java)))) Semak lokasi java_home
Semak lokasi java_home
Langkah 2: Buat Pengguna untuk Hadoop
Semua komponen Hadoop akan dijalankan sebagai pengguna yang anda buat untuk Apache Hadoop, dan pengguna juga akan digunakan untuk log masuk ke antara muka web Hadoop. Anda boleh membuat akaun pengguna baru dengan arahan "sudo" atau anda boleh membuat akaun pengguna dengan kebenaran "root". Akaun Pengguna dengan Kebenaran Root lebih selamat tetapi mungkin tidak mudah bagi pengguna yang tidak biasa dengan baris arahan.
- Jalankan arahan berikut untuk membuat pengguna baru dengan namanya "Hadoop":
Sudo Adduser Hadoop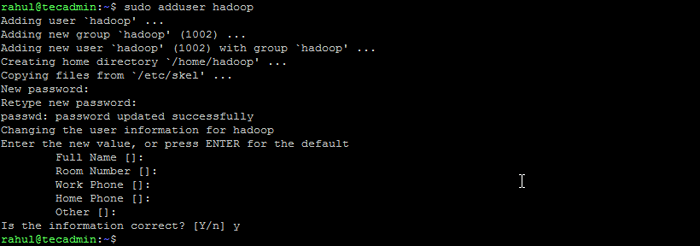 Buat pengguna Hadoop
Buat pengguna Hadoop - Beralih ke pengguna Hadoop yang baru dibuat:
Su - Hadoop - Sekarang konfigurasikan akses SSH yang kurang kata laluan untuk pengguna Hadoop yang baru dibuat. Menjana keypair SSH terlebih dahulu:
SSH -KEYGEN -T RSA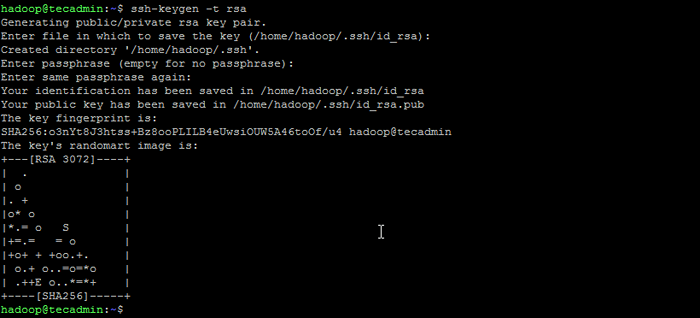 Menjana pasangan kunci ssh
Menjana pasangan kunci ssh - Salin kunci awam yang dihasilkan ke fail kunci yang dibenarkan dan tetapkan keizinan yang betul:
kucing ~/.SSH/ID_RSA.pub >> ~/.SSH/Authorized_keyschmod 640 ~/.SSH/Authorized_keys - Sekarang cuba ssh ke localhost.
SSH LocalhostAnda akan diminta untuk mengesahkan tuan rumah dengan menambah kekunci RSA kepada tuan rumah yang diketahui. Taipkan ya dan tekan Enter untuk mengesahkan localhost:
 Sambungkan SSH ke Localhost
Sambungkan SSH ke Localhost
Langkah 3: Pasang Hadoop di Ubuntu
Sebaik sahaja anda memasang Java, anda boleh memuat turun Apache Hadoop dan semua komponennya yang berkaitan, termasuk sarang, babi, sqoop, dll. Anda boleh mencari versi terkini di halaman muat turun Hadoop rasmi. Pastikan untuk memuat turun arkib binari (bukan sumber).
- Gunakan arahan berikut untuk memuat turun Hadoop 3.3.4:
wget https: // dlcdn.Apache.Org/Hadoop/Common/Hadoop-3.3.4/Hadoop-3.3.4.tar.Gz - Sebaik sahaja anda telah memuat turun fail, anda boleh menyahut ke folder pada cakera keras anda.
tar xzf Hadoop-3.3.4.tar.Gz - Namakan semula folder yang diekstrak untuk mengalih keluar maklumat versi. Ini adalah langkah pilihan, tetapi jika anda tidak mahu menamakan semula, maka sesuaikan laluan konfigurasi yang tinggal.
MV Hadoop-3.3.4 Hadoop - Seterusnya, anda perlu mengkonfigurasi pembolehubah persekitaran Hadoop dan Java pada sistem anda. Buka ~/.Fail Bashrc dalam editor teks kegemaran anda:
nano ~/.BashrcTambahkan baris di bawah ke fail. Anda boleh mencari lokasi java_home dengan berjalan
eksport java_home =/usr/lib/jvm/java-11-opengdk-amd64 eksport hadoop_home =/home/hadoop/hadoop eksport hadoop_install = $ Hadoop_Home Export Hadoop_Mapred_Home = $ hasoop_home_home_home_home_home_home_home_home_home_home_home Hadoop_Home Export Hadoop_Common_Lib_native_dir = $ Hadoop_Home/lib/Laluan Eksport asli = $ Path: $ Hadoop_Home/Sbin: $ Hadoop_Home/Bin Export Hadoop_opts = "-Djava.Perpustakaan.Path = $ hadoop_home/lib/asli "Dirname $ (dirname $ (readlink -f $ (yang java))))perintah di terminal.12345678910 export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64export HADOOP_HOME=/home/hadoop/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/ Lib/NativeXport Path = $ Path: $ Hadoop_Home/Sbin: $ Hadoop_Home/BineXport Hadoop_Opts = "-Djava.Perpustakaan.Path = $ hadoop_home/lib/asli " Simpan fail dan tutupnya.
- Muatkan konfigurasi di atas dalam persekitaran semasa.
sumber ~/.Bashrc - Anda juga perlu mengkonfigurasi Java_home dalam Hadoop-ENV.sh fail. Edit fail pembolehubah persekitaran Hadoop dalam editor teks:
Nano $ Hadoop_Home/etc/Hadoop/Hadoop-ENV.shCari "Eksport Java_Home" dan konfigurasikannya dengan nilai yang terdapat di Langkah 1. Lihat tangkapan skrin di bawah:
 Tetapkan java_home
Tetapkan java_homeSimpan fail dan tutupnya.
Langkah 4: Mengkonfigurasi Hadoop
Seterusnya adalah untuk mengkonfigurasi fail konfigurasi Hadoop yang terdapat di bawah direktori ETC.
- Pertama, anda perlu membuat namenode dan DataNode Direktori di dalam direktori rumah pengguna Hadoop. Jalankan arahan berikut untuk membuat kedua -dua direktori:
mkdir -p ~/hadoopdata/hdfs/namenode, datanode - Seterusnya, edit tapak teras.XML fail dan kemas kini dengan nama hos sistem anda:
nano $ hadoop_home/etc/hadoop/tapak teras.XMLTukar nama berikut mengikut nama hos sistem anda:
fs.defaultfs hdfs: // localhost: 9000123456 fs.defaultfs hdfs: // localhost: 9000 Simpan dan tutup fail.
- Kemudian, edit tapak HDFS.XML Fail:
nano $ hadoop_home/etc/hadoop/hdfs-site.XMLTukar laluan direktori Namenode dan Datanode seperti yang ditunjukkan di bawah:
DFS.Replikasi 1 DFS.nama.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/Namenode DFS.data.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode12345678910111213141516 DFS.Replikasi 1 DFS.nama.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/Namenode DFS.data.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode Simpan dan tutup fail.
- Kemudian, edit tapak peta.XML Fail:
nano $ hadoop_home/etc/hadoop/mapred-site.XMLBuat perubahan berikut:
MapReduce.Rangka Kerja.Nama benang123456 MapReduce.Rangka Kerja.Nama benang Simpan dan tutup fail.
- Kemudian, edit tapak benang.XML Fail:
nano $ hadoop_home/etc/hadoop/tapak benang.XMLBuat perubahan berikut:
Benang.Nodemanager.Aux-Services MapReduce_Shuffle123456 Benang.Nodemanager.Aux-Services MapReduce_Shuffle Simpan fail dan tutupnya.
Langkah 5: Mula Cluster Hadoop
Sebelum memulakan kluster Hadoop. Anda perlu memformat namenode sebagai pengguna Hadoop.
- Jalankan arahan berikut untuk memformat Hadoop Namenode:
HDFS namenode -FormatSetelah direktori namenode berjaya diformat dengan sistem fail HDFS, anda akan melihat mesej "Direktori Penyimpanan/Rumah/Hadoop/Hadoopdata/HDFS/Namenode telah berjaya diformat".
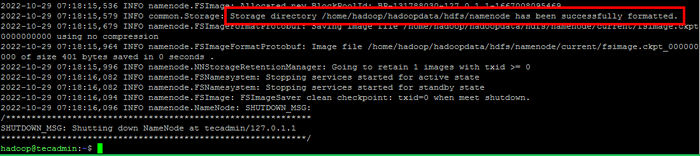 Format namenode
Format namenode - Kemudian mulakan kluster Hadoop dengan arahan berikut.
mula-semua.sh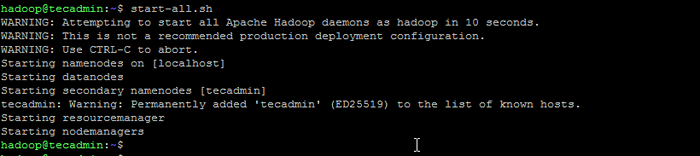 Mula perkhidmatan Hadoop
Mula perkhidmatan Hadoop - Sebaik sahaja semua perkhidmatan bermula, anda boleh mengakses Hadoop di: http: // localhost: 9870

- Dan Halaman Aplikasi Hadoop boleh didapati di http: // localhost: 8088

Kesimpulan
Memasang Apache Hadoop di Ubuntu boleh menjadi tugas yang rumit untuk pemula, terutamanya jika mereka hanya mengikuti arahan dalam dokumentasi. Syukurlah, artikel ini menyediakan panduan langkah demi langkah yang akan membantu anda memasang Apache Hadoop di Ubuntu dengan mudah. Yang harus anda lakukan adalah mengikuti arahan yang disenaraikan dalam artikel ini, dan anda pasti bahawa pemasangan Hadoop anda akan berjalan dan berjalan dalam masa yang singkat.