

Cara Memasang dan Menyediakan Apache Spark di Ubuntu/Debian

- 3626
- 323
- Daryl Wilderman
Apache Spark adalah rangka kerja pengiraan yang diedarkan sumber terbuka yang dibuat untuk memberikan hasil pengiraan yang lebih cepat. Ini adalah enjin pengiraan dalam memori, yang bermaksud data akan diproses dalam ingatan.
Percikan Menyokong pelbagai API untuk streaming, pemprosesan graf, sql, mllib. Ia juga menyokong Java, Python, Scala, dan R sebagai bahasa pilihan. Spark kebanyakannya dipasang dalam kelompok Hadoop tetapi anda juga boleh memasang dan mengkonfigurasi percikan dalam mod mandiri.
Dalam artikel ini, kita akan melihat cara memasang Apache Spark dalam Debian dan Ubuntu-pengagihan berasaskan.
Pasang Java dan Scala di Ubuntu
Untuk memasang Apache Spark Di Ubuntu, anda perlu mempunyai Java dan Scala dipasang di mesin anda. Sebilangan besar pengagihan moden disertakan dengan Java yang dipasang secara lalai dan anda boleh mengesahkannya menggunakan arahan berikut.
$ java -versi
 Semak versi Java di Ubuntu
Semak versi Java di Ubuntu Jika tiada output, anda boleh memasang Java menggunakan artikel kami tentang cara memasang Java di Ubuntu atau hanya menjalankan arahan berikut untuk memasang Java di Ubuntu dan pengagihan berasaskan Debian.
$ sudo apt update $ sudo apt memasang lalai -jre $ java -version
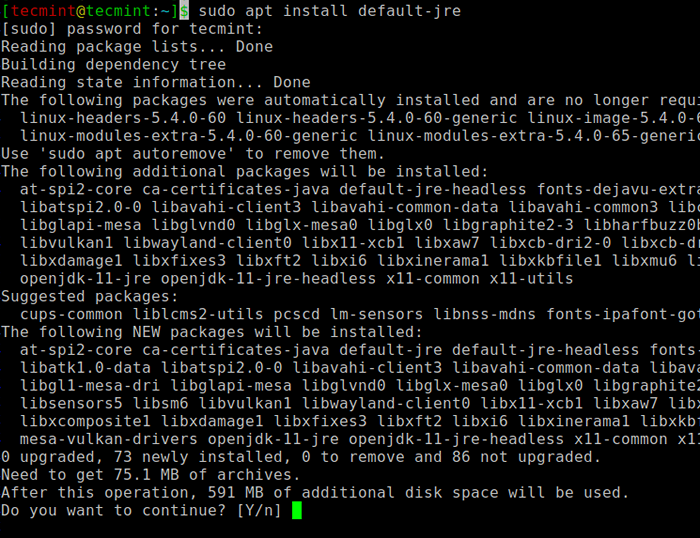 Pasang Java di Ubuntu
Pasang Java di Ubuntu Seterusnya, anda boleh memasang Scala dari repositori apt dengan menjalankan perintah berikut untuk mencari Scala dan pasangkannya.
$ sudo apt carian scala ⇒ cari pakej $ sudo apt install scala ⇒ pasangkan pakej
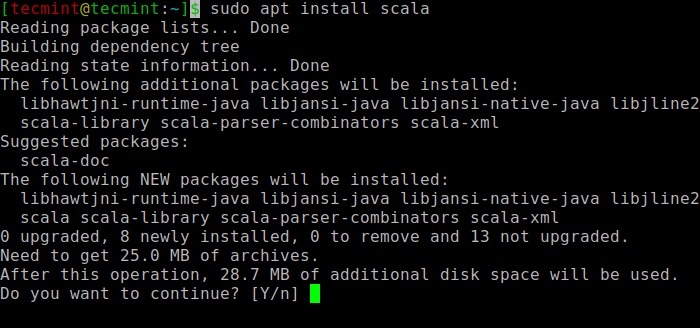 Pasang Scala di Ubuntu
Pasang Scala di Ubuntu Untuk mengesahkan pemasangan Scala, Jalankan arahan berikut.
$ scala -version Versi 2 Runner Code 2.11.12-Hak Cipta 2002-2017, Lamp/EPFL
Pasang Apache Spark di Ubuntu
Sekarang pergi ke halaman muat turun Apache Spark rasmi dan ambil versi terkini (i.e. 3.1.1) Pada masa menulis artikel ini. Sebagai alternatif, anda boleh menggunakan arahan wget untuk memuat turun fail secara langsung di terminal.
$ wget https: // Apachemirror.Wuchna.com/Spark/Spark-3.1.1/Spark-3.1.1-bin-Hadoop2.7.TGZ
Sekarang buka terminal anda dan beralih ke tempat fail yang dimuat turun anda diletakkan dan jalankan arahan berikut untuk mengekstrak fail tar Apache Spark.
$ tar -xvzf Spark -3.1.1-bin-Hadoop2.7.TGZ
Akhirnya, gerakkan yang diekstrak Percikan direktori ke /Memilih direktori.
$ sudo mv spark-3.1.1-bin-Hadoop2.7 /opt /percikan api
Konfigurasikan pembolehubah persekitaran untuk percikan api
Sekarang anda perlu menetapkan beberapa pembolehubah persekitaran di anda .profil fail sebelum memulakan percikan api.
$ echo "export spark_home =/opt/spark" >> ~/.profil $ echo "laluan eksport = $ path:/opt/spark/bin:/opt/percikan/sbin" >> ~/.profil $ echo "eksport pyspark_python =/usr/bin/python3" >> ~/.profil
Untuk memastikan bahawa pembolehubah persekitaran baru ini dapat dicapai dalam shell dan tersedia untuk Apache Spark, ia juga wajib untuk menjalankan perintah berikut untuk mengambil perubahan baru -baru ini.
$ sumber ~/.profil
Semua binari yang berkaitan dengan percikan untuk memulakan dan menghentikan perkhidmatan di bawah sbin folder.
$ ls -l /opt /percikan api
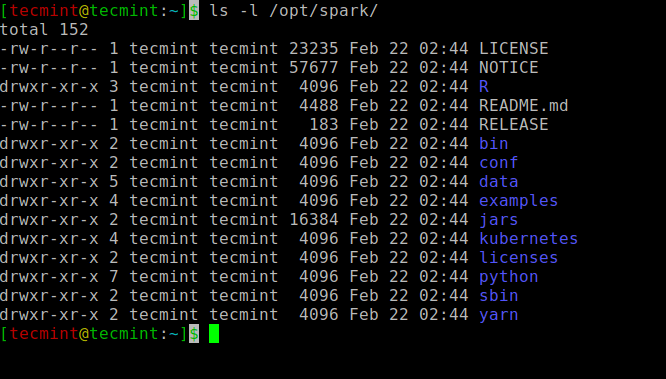 Binari percikan
Binari percikan Mulakan Apache Spark di Ubuntu
Jalankan arahan berikut untuk memulakan Percikan perkhidmatan induk dan perkhidmatan hamba.
$ start-master.SH $ Start-workers.SH Spark: // Localhost: 7077
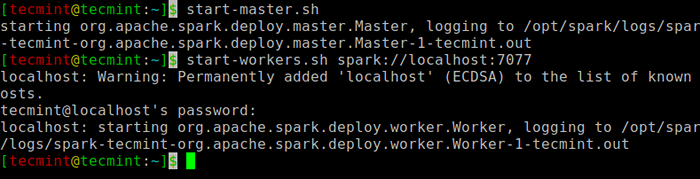 Mulakan perkhidmatan percikan
Mulakan perkhidmatan percikan Sebaik sahaja perkhidmatan dimulakan pergi ke penyemak imbas dan taipkan halaman Spark Akses URL berikut. Dari halaman, anda dapat melihat perkhidmatan tuan dan hamba saya dimulakan.
http: // localhost: 8080/atau http: // 127.0.0.1: 8080
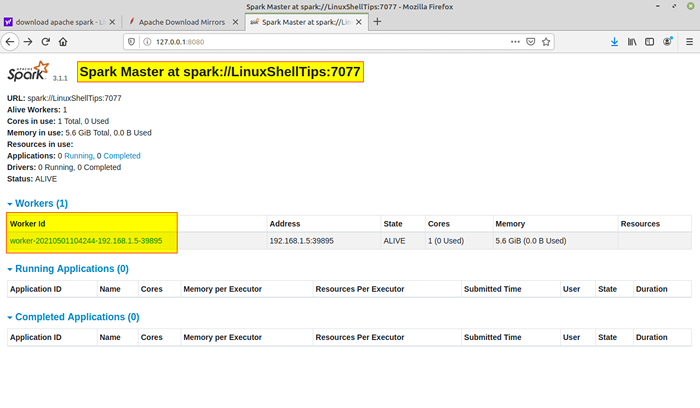 Laman web percikan
Laman web percikan Anda juga boleh menyemak sama ada Spark-shell berfungsi dengan baik dengan melancarkan Spark-shell perintah.
$ Spark-shell
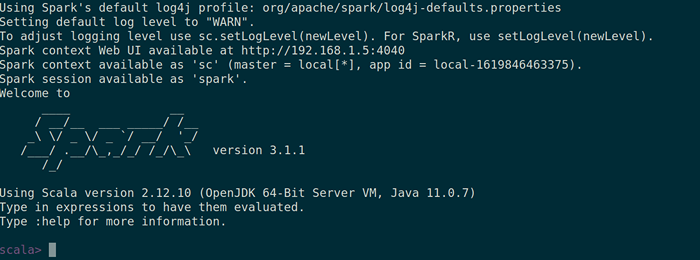 Spark Shell
Spark Shell Itu sahaja untuk artikel ini. Kami akan menangkap anda dengan artikel lain yang menarik tidak lama lagi.
- « LFCA Belajar Kos dan Belanjawan - Bahagian 16
- Cara Memantau Pelayan Linux Dan Metrik Proses Dari Penyemak Imbas »