

Cara Memasang dan Konfigurasi Hadoop di CentOS/RHEL 8

- 3160
- 275
- Marcus Kassulke
Hadoop adalah rangka kerja perisian berasaskan sumber bebas, sumber terbuka dan Java yang digunakan untuk penyimpanan dan pemprosesan dataset besar pada kelompok mesin. Ia menggunakan HDFS untuk menyimpan data dan memproses data ini menggunakan MapReduce. Ini adalah ekosistem alat data besar yang digunakan terutamanya untuk perlombongan data dan pembelajaran mesin. Ia mempunyai empat komponen utama seperti Hadoop Common, HDFS, Benang, dan MapReduce.
Dalam panduan ini, kami akan menerangkan cara memasang Apache Hadoop di RHEL/CentOS 8.
Langkah 1 - Lumpuhkan selinux
Sebelum memulakan, adalah idea yang baik untuk melumpuhkan selinux dalam sistem anda.
Untuk melumpuhkan selinux, buka fail/etc/selinux/config:
nano/etc/selinux/config
Tukar baris berikut:
Selinux = dilumpuhkan
Simpan fail apabila anda selesai. Seterusnya, mulakan semula sistem anda untuk menggunakan perubahan selinux.
Langkah 2 - Pasang Java
Hadoop ditulis di Java dan hanya menyokong versi Java 8. Anda boleh memasang OpenJDK 8 dan semut menggunakan arahan DNF seperti yang ditunjukkan di bawah:
DNF Pasang Java-1.8.0 -OpenJdk Ant -y
Setelah dipasang, sahkan versi Java yang dipasang dengan arahan berikut:
java -versi
Anda harus mendapatkan output berikut:
Versi OpenJDK "1.8.0_232 "Persekitaran Runtime OpenJDK (membina 1.8.0_232-b09) VM pelayan OpenJDK 64-bit (membina 25.232-B09, Mod Campuran)
Langkah 3 - Buat pengguna Hadoop
Adalah idea yang baik untuk membuat pengguna yang berasingan untuk menjalankan Hadoop atas alasan keselamatan.
Jalankan arahan berikut untuk membuat pengguna baru dengan nama Hadoop:
UserAdd Hadoop
Seterusnya, tetapkan kata laluan untuk pengguna ini dengan arahan berikut:
Passwd Hadoop
Sediakan dan sahkan kata laluan baru seperti yang ditunjukkan di bawah:
Menukar kata laluan untuk pengguna hadoop. Kata Laluan Baru: Retype Kata Laluan Baru: Passwd: Semua Token Pengesahan Dikemas kini dengan jayanya.
Langkah 4 - Konfigurasikan pengesahan berasaskan kunci SSH
Seterusnya, anda perlu mengkonfigurasi pengesahan SSH tanpa kata laluan untuk sistem tempatan.
Pertama, ubah pengguna ke Hadoop dengan arahan berikut:
Su - Hadoop
Seterusnya, jalankan arahan berikut untuk menjana pasangan utama awam dan swasta:
SSH -KEYGEN -T RSA
Anda akan diminta memasukkan nama fail. Cukup tekan Enter untuk menyelesaikan proses:
Menjana pasangan kunci RSA awam/swasta. Masukkan fail di mana untuk menyimpan kunci (/rumah/hadoop/.ssh/id_rsa): direktori '/rumah/hadoop/.ssh '. Masukkan frasa laluan (kosong tanpa frasa laluan): Masukkan frasa laluan yang sama sekali lagi: pengenalan anda telah disimpan di/rumah/hadoop/.SSH/ID_RSA. Kunci awam anda telah diselamatkan di/rumah/hadoop/.SSH/ID_RSA.pub. Cap jari utama ialah: SHA256: A/OG+N3CNBSSYE1ULKK95GYS0POOC0DVJ+YH1DFZPF8 [E-mel dilindungi] Imej rawak utama adalah:+--- [RSA 2048] ----+| | | | | . | | . O O O | | ... o s o o | | o = + o o . | | o * o = b = . | | + O.O.O + + . | | +=*ob.+ o e | +---- [SHA256]-----+
Seterusnya, tambahkan kunci awam yang dihasilkan dari ID_RSA.pub ke kuasa yang diberi kuasa dan menetapkan kebenaran yang betul:
kucing ~/.SSH/ID_RSA.pub >> ~/.SSH/Authorized_keys chmod 640 ~/.SSH/Authorized_keys
Seterusnya, sahkan pengesahan SSH tanpa kata laluan dengan arahan berikut:
SSH Localhost
Anda akan diminta untuk mengesahkan tuan rumah dengan menambah kekunci RSA kepada tuan rumah yang diketahui. Taipkan ya dan tekan Enter untuk mengesahkan localhost:
Kesahihan tuan rumah 'localhost (:: 1)' tidak dapat ditubuhkan. Cap jari utama ECDSA ialah SHA256: 0yr1kdgu4443phn2genuzsvrjbbpjat3bdrdr3mw. Adakah anda pasti mahu terus menyambung (ya/tidak)? Ya Amaran: Menambah 'localhost' (ECDSA) secara kekal ke senarai tuan rumah yang diketahui. Aktifkan Konsol Web dengan: SistemCtl Enable --now Cockpit.Soket Log Masuk Terakhir: Sat Feb 1 02:48:55 2020 [[E -mel dilindungi] ~] $
Langkah 5 - Pasang Hadoop
Pertama, ubah pengguna ke Hadoop dengan arahan berikut:
Su - Hadoop
Seterusnya, muat turun versi terkini Hadoop menggunakan perintah wget:
wget http: // Apachemirror.Wuchna.com/Hadoop/Common/Hadoop-3.2.1/Hadoop-3.2.1.tar.Gz
Setelah dimuat turun, ekstrak fail yang dimuat turun:
tar -xvzf Hadoop -3.2.1.tar.Gz
Seterusnya, namakan semula direktori yang diekstrak ke Hadoop:
MV Hadoop-3.2.1 Hadoop
Seterusnya, anda perlu mengkonfigurasi pembolehubah persekitaran Hadoop dan Java pada sistem anda.
Buka ~/.Fail Bashrc dalam editor teks kegemaran anda:
nano ~/.Bashrc
Tambahkan baris berikut:
Eksport java_home =/usr/lib/jvm/jre-1.8.0-OpenJDK-1.8.0.232.B09-2.EL8_1.x86_64/ export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH : $ Hadoop_home/sbin: $ hadoop_home/bin eksport hadoop_opts = "-Djava.Perpustakaan.Path = $ hadoop_home/lib/asli "
Simpan dan tutup fail. Kemudian, aktifkan pembolehubah persekitaran dengan arahan berikut:
sumber ~/.Bashrc
Seterusnya, buka fail pembolehubah persekitaran Hadoop:
Nano $ Hadoop_Home/etc/Hadoop/Hadoop-ENV.sh
Kemas kini pemboleh ubah java_home mengikut laluan pemasangan java anda:
Eksport java_home =/usr/lib/jvm/jre-1.8.0-OpenJDK-1.8.0.232.B09-2.EL8_1.x86_64/
Simpan dan tutup fail apabila anda selesai.
Langkah 6 - Konfigurasikan Hadoop
Pertama, anda perlu membuat direktori Namenode dan Datanode di dalam direktori rumah Hadoop:
Jalankan arahan berikut untuk membuat kedua -dua direktori:
mkdir -p ~/hadoopdata/hdfs/namenode mkdir -p ~/hadoopdata/hdfs/datanode
Seterusnya, edit tapak teras.XML fail dan kemas kini dengan nama hos sistem anda:
nano $ hadoop_home/etc/hadoop/tapak teras.XML
Tukar nama berikut mengikut nama hos sistem anda:
fs.Defaultfs HDFS: // Hadoop.Tecadmin.com: 9000| 123456 | fs.Defaultfs HDFS: // Hadoop.Tecadmin.com: 9000 |
Simpan dan tutup fail. Kemudian, edit tapak HDFS.XML Fail:
nano $ hadoop_home/etc/hadoop/hdfs-site.XML
Tukar laluan direktori Namenode dan Datanode seperti yang ditunjukkan di bawah:
DFS.Replikasi 1 DFS.nama.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/Namenode DFS.data.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode| 1234567891011121314151617 | DFS.Replikasi 1 DFS.nama.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/Namenode DFS.data.Fail dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode |
Simpan dan tutup fail. Kemudian, edit tapak peta.XML Fail:
nano $ hadoop_home/etc/hadoop/mapred-site.XML
Buat perubahan berikut:
MapReduce.Rangka Kerja.Nama benang| 123456 | MapReduce.Rangka Kerja.Nama benang |
Simpan dan tutup fail. Kemudian, edit tapak benang.XML Fail:
nano $ hadoop_home/etc/hadoop/tapak benang.XML
Buat perubahan berikut:
Benang.Nodemanager.Aux-Services MapReduce_Shuffle| 123456 | Benang.Nodemanager.Aux-Services MapReduce_Shuffle |
Simpan dan tutup fail apabila anda selesai.
Langkah 7 - Mula Cluster Hadoop
Sebelum memulakan kluster Hadoop. Anda perlu memformat namenode sebagai pengguna Hadoop.
Jalankan arahan berikut untuk memformat Hadoop Namenode:
HDFS namenode -Format
Anda harus mendapatkan output berikut:
2020-02-05 03: 10: 40,380 maklumat namenode.NnstorageretentionManager: akan mengekalkan 1 imej dengan txid> = 0 2020-02-05 03: 10: 40,389 maklumat namenode.Fsimage: fsimagesaver clean checkpoint: txid = 0 Apabila memenuhi penutupan. 2020-02-05 03: 10: 40,389 Maklumat Namenode.Namenode: shutdown_msg: /*********************************************** *************** Shutdown_msg: Menutup Namenode di Hadoop.Tecadmin.com/45.58.38.202 ***************************************************** *************/
Selepas membentuk namenode, jalankan arahan berikut untuk memulakan kluster Hadoop:
start-dfs.sh
Setelah HDFS bermula dengan jayanya, anda harus mendapatkan output berikut:
Memulakan Namenodes di [Hadoop.Tecadmin.com] Hadoop.Tecadmin.com: Amaran: Menambah 'Hadoop secara kekal.Tecadmin.com, Fe80 :: 200: 2DFF: Fe3A: 26ca%ETH0 '(ECDSA) ke senarai tuan rumah yang diketahui. Memulakan Datanodes Memulakan Namenode Menengah [Hadoop.Tecadmin.com]
Seterusnya, mulakan perkhidmatan benang seperti yang ditunjukkan di bawah:
Start-Yarn.sh
Anda harus mendapatkan output berikut:
Memulakan ResourceManager Memulakan Nodemanagers
Anda kini boleh menyemak status semua perkhidmatan Hadoop menggunakan arahan JPS:
JPS
Anda harus melihat semua perkhidmatan yang berjalan dalam output berikut:
7987 Datanode 9606 JPS 8183 Secondarynamenode 8570 Nodemanager 8445 ResourceManager 7870 Namenode
Langkah 8 - Konfigurasikan firewall
Hadoop kini bermula dan mendengar di Port 9870 dan 8088. Seterusnya, anda perlu membenarkan pelabuhan ini melalui firewall.
Jalankan arahan berikut untuk membolehkan sambungan Hadoop melalui firewall:
Firewall-CMD --PerManent --Add-Port = 9870/TCP Firewall-CMD --PerManent --Add-Port = 8088/TCP
Seterusnya, tambah semula perkhidmatan Firewalld untuk memohon perubahan:
Firewall-CMD-Reload
Langkah 9 - Akses Hadoop Namenode dan Pengurus Sumber
Untuk mengakses namenode, buka penyemak imbas web anda dan lawati URL http: // your-server-ip: 9870. Anda mesti melihat skrin berikut:
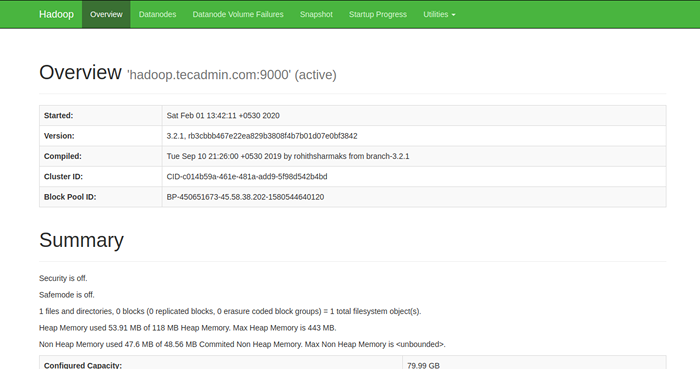
Untuk mengakses sumber menguruskan, buka penyemak imbas web anda dan lawati URL http: // your-server-ip: 8088. Anda mesti melihat skrin berikut:
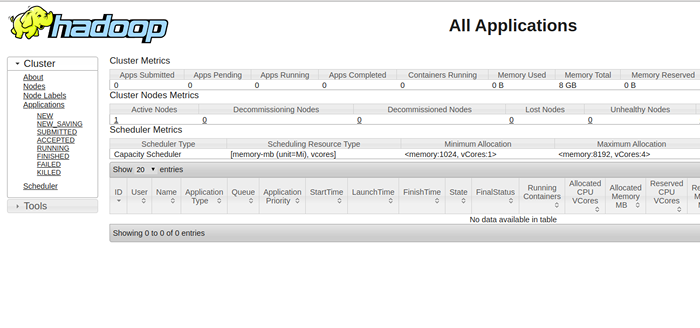
Langkah 10 - Sahkan kelompok Hadoop
Pada ketika ini, kluster Hadoop dipasang dan dikonfigurasikan. Seterusnya, kami akan membuat beberapa direktori dalam sistem fail HDFS untuk menguji Hadoop.
Mari buat beberapa direktori dalam sistem fail HDFS menggunakan arahan berikut:
HDFS DFS -MKDIR /TEST1 HDFS DFS -MKDIR /TEST2
Seterusnya, jalankan arahan berikut untuk menyenaraikan direktori di atas:
HDFS DFS -LS /
Anda harus mendapatkan output berikut:
Ditemui 2 item DRWXR-XR-X-Hadoop Supergroup 0 2020-02-05 03:25 /TEST1 DRWXR-XR-X-Hadoop Supergroup 0 2020-02-05 03:35 /TEST2
Anda juga boleh mengesahkan direktori di atas di antara muka web Hadoop Namenode.
Pergi ke antara muka web Namenode, klik pada utiliti => Semak imbas sistem fail. Anda harus melihat direktori anda yang telah anda buat sebelum ini dalam skrin berikut:
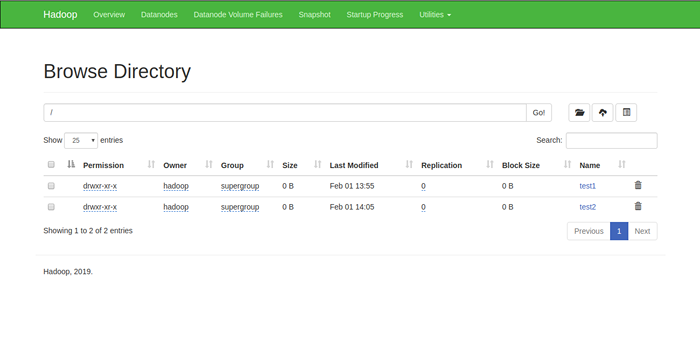
Langkah 11 - Hentikan kluster Hadoop
Anda juga boleh menghentikan perkhidmatan Namenode dan Benang Hadoop pada bila -bila masa dengan menjalankan Stop-DFS.sh dan Stop-Yarn.sh Skrip sebagai pengguna Hadoop.
Untuk menghentikan perkhidmatan Hadoop Namenode, jalankan arahan berikut sebagai pengguna Hadoop:
Stop-DFS.sh
Untuk menghentikan perkhidmatan Pengurus Sumber Hadoop, jalankan arahan berikut:
Stop-Yarn.sh
Kesimpulan
Dalam tutorial di atas, anda belajar bagaimana untuk menubuhkan kluster nod tunggal Hadoop di CentOS 8. Saya harap anda mempunyai pengetahuan yang cukup untuk memasang Hadoop dalam persekitaran pengeluaran.