

Cara memasang dan mengkonfigurasi Apache Hadoop pada nod tunggal di CentOS 7

- 2210
- 346
- Noah Torp
Apache Hadoop adalah rangka kerja sumber terbuka yang dibina untuk disebarkan data penyimpanan dan pemprosesan data besar di seluruh kluster komputer. Projek ini berdasarkan komponen berikut:
- Hadoop biasa - ia mengandungi perpustakaan dan utiliti Java yang diperlukan oleh modul Hadoop yang lain.
- HDFS - Hadoop diedarkan sistem fail - sistem fail berskala berasaskan Java yang diedarkan di beberapa nod.
- MapReduce - Rangka Kerja Benang untuk Pemprosesan Data Besar Selari.
- Benang Hadoop: Rangka kerja untuk pengurusan sumber kluster.
Pasang Hadoop di CentOS 7 Artikel ini akan membimbing anda bagaimana anda boleh memasang Apache Hadoop pada satu kluster nod tunggal di Centos 7 (Juga berfungsi untuk RHEL 7 dan Fedora 23+ versi). Konfigurasi jenis ini juga dirujuk sebagai Mod yang diedarkan pseudo Hadoop.
Langkah 1: Pasang Java di CentOS 7
1. Sebelum meneruskan dengan pemasangan Java, log masuk pertama dengan pengguna root atau pengguna dengan keistimewaan root menyediakan nama hos mesin anda dengan arahan berikut.
# HostNamectl Set-Hostname Master
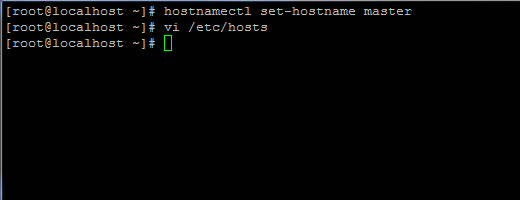 Tetapkan nama hos di CentOS 7
Tetapkan nama hos di CentOS 7 Juga, tambahkan rekod baru dalam fail hos dengan mesin anda sendiri FQDN untuk menunjuk ke alamat IP sistem anda.
# vi /etc /hosts
Tambahkan garis di bawah:
192.168.1.41 tuan.Hadoop.lan
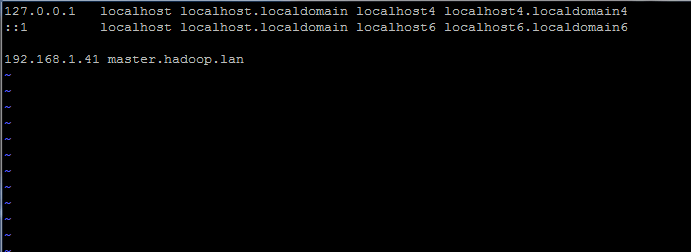 Tetapkan nama host dalam /etc /hosts fail
Tetapkan nama host dalam /etc /hosts fail Ganti nama host dan rekod FQDN di atas dengan tetapan anda sendiri.
2. Seterusnya, pergi ke halaman muat turun Oracle Java dan ambil versi terkini Kit Pembangunan Java Se 8 pada sistem anda dengan bantuan curl Perintah:
# curl -lo -h "cookie: oraclelicense = accept -securebackup -cookie" "http: // muat turun.Oracle.com/OTN-PUB/Java/JDK/8U92-B14/JDK-8U92-LINUX-X64.rpm ”
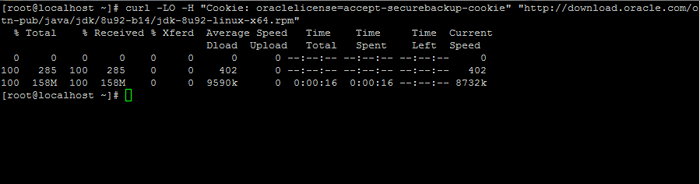 Muat turun Kit Pembangunan Java Se 8
Muat turun Kit Pembangunan Java Se 8 3. Setelah selesai muat turun Java Binary, pasangkan pakej dengan mengeluarkan arahan di bawah:
# RPM -UVH JDK-8U92-LINUX-X64.rpm
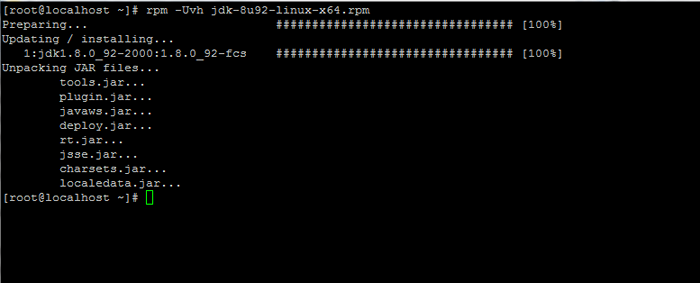 Pasang Java di CentOS 7
Pasang Java di CentOS 7 Langkah 2: Pasang Rangka Kerja Hadoop di CentOS 7
4. Seterusnya, buat akaun pengguna baru di sistem anda tanpa kuasa root yang kami akan gunakan untuk laluan pemasangan Hadoop dan persekitaran kerja. Direktori rumah akaun baru akan tinggal di /Opt/Hadoop direktori.
# USERADD -D /OPT /Hadoop Hadoop # Passwd Hadoop
5. Pada langkah seterusnya, lawati halaman Apache Hadoop untuk mendapatkan pautan untuk versi stabil terkini dan muat turun arkib pada sistem anda.
# curl -o http: // apache.Javapipe.com/Hadoop/Common/Hadoop-2.7.2/Hadoop-2.7.2.tar.Gz
 Muat turun pakej Hadoop
Muat turun pakej Hadoop 6. Ekstrak Arkib Salinan Kandungan Direktori ke Laluan Rumah Akaun Hadoop. Juga, pastikan anda menukar keizinan fail yang disalin dengan sewajarnya.
# tar xfz Hadoop-2.7.2.tar.GZ # CP -RF Hadoop -2.7.2/*/opt/hadoop/ # chown -r hadoop: hadoop/opt/hadoop/
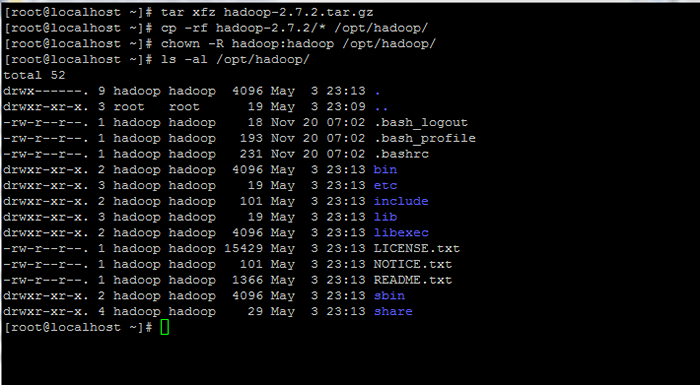 Ekstrak dan set kebenaran di Hadoop
Ekstrak dan set kebenaran di Hadoop 7. Seterusnya, log masuk dengan Hadoop pengguna dan konfigurasikan Hadoop dan Pembolehubah persekitaran Java pada sistem anda dengan mengedit .BASH_PROFILE fail.
# Su - Hadoop $ VI .BASH_PROFILE
Tambahkan baris berikut pada akhir fail:
## Java Env Variables Eksport java_home =/usr/java/jalur eksport lalai = $ path: $ java_home/bin eksport classpath =.: $ Java_home/jre/lib: $ java_home/lib: $ java_home/lib/alat.balang ## pembolehubah env hadoop Eksport HADOOP_HOME =/OPT/HADOOP Eksport HADOOP_COMMON_HOME = $ HADOOP_HOME EXPORT HADOOP_HDFS_HOME = $ HADOOP_HOME EXPOR.Perpustakaan.PATH = $ HADOOP_HOME/LIB/NATIVE "Eksport HADOOP_COMMON_LIB_NATIVE_DIR = $ HADOOP_HOME/LIB/NATIVE EXPORT PATH = $ PATH: $ HADOOP_HOME/SBIN: $ HADOOP_HOME/BIN/BIN
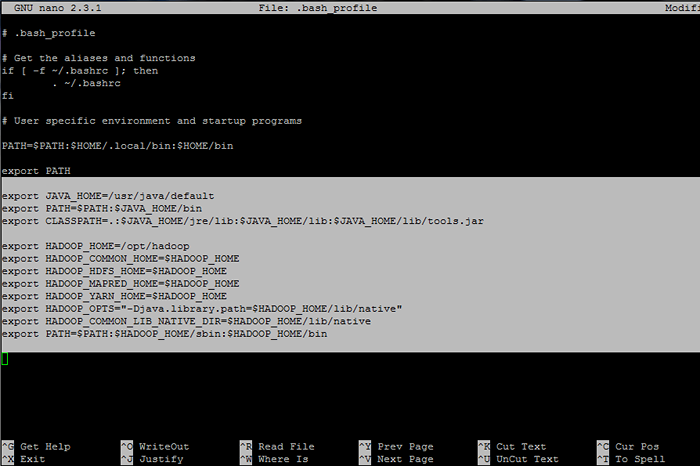 Konfigurasikan pembolehubah persekitaran Hadoop dan Java
Konfigurasikan pembolehubah persekitaran Hadoop dan Java 8. Sekarang, mulakan pembolehubah persekitaran dan periksa status mereka dengan mengeluarkan arahan di bawah:
$ sumber .bash_profile $ echo $ hadoop_home $ echo $ java_home
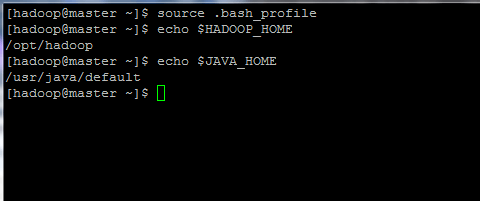 Memulakan pembolehubah persekitaran linux
Memulakan pembolehubah persekitaran linux 9. Akhirnya, konfigurasikan pengesahan berasaskan kunci SSH untuk Hadoop akaun dengan menjalankan arahan di bawah (ganti Nama Host atau FQDN terhadap SSH-COPY-ID perintah dengan sewajarnya).
Juga, tinggalkan laluan belakang Difailkan kosong untuk log masuk secara automatik melalui SSH.
$ ssh-keygen -t rsa $ ssh-copy-id Master.Hadoop.lan
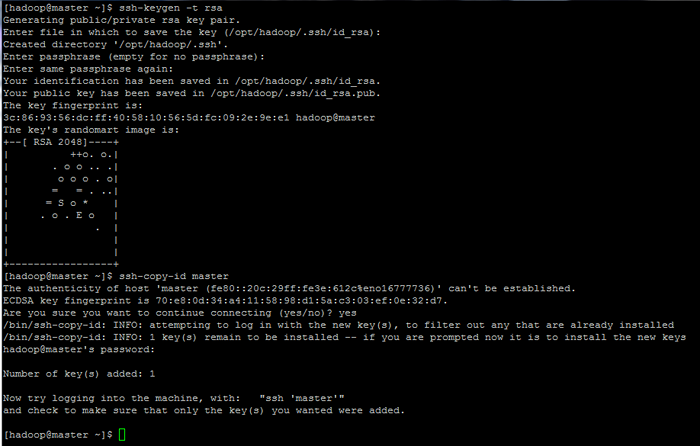 Konfigurasikan Halaman Pengesahan Berdasarkan Kunci SSH: 1 2 3
Konfigurasikan Halaman Pengesahan Berdasarkan Kunci SSH: 1 2 3
- « Cari 10 alamat IP teratas yang mengakses pelayan web Apache anda
- 10 Soalan Temuduga Berguna mengenai Perkhidmatan dan Daemon Linux »