

Hadoop - menjalankan contoh MapReduce WordCount
- 4325
- 808
- Wendell Shields
Tutorial ini akan membantu anda menjalankan contoh MapReduce WordCount di Hadoop menggunakan baris arahan. Ini juga boleh menjadi ujian awal untuk ujian persediaan Hadoop anda.
1. Prasyarat
Anda mesti menjalankan persediaan Hadoop pada sistem anda. Sekiranya anda tidak memasang pemasangan pemasangan Hadoop Hadoop pada tutorial Linux.
2. Salin fail ke sistem fail namenode
Setelah berjaya memformat Namenode, anda mesti memulakan semua perkhidmatan Hadoop dengan betul. Sekarang buat direktori di sistem fail Hadoop.
$ hdfs dfs -mkdir -p/user/hadoop/input
Salin Salin Beberapa Fail Teks ke Hadoop Filesystem di dalam direktori input. Di sini saya menyalin lesen.txt kepadanya. Anda boleh menyalin lebih banyak fail.
$ HDFS DFS -put Lesen.TXT/USER/HADOOP/INPUT/
3. Running WordCount Command
Sekarang jalankan contoh WordCount MapReduce menggunakan arahan berikut. Perintah di bawah akan membaca semua fail dari folder input dan proses dengan fail balang mapreduce. Setelah berjaya menyelesaikan keputusan tugas akan diletakkan di direktori output.
$ cd $ Hadoop_home $ Hadoop balang Share/Hadoop/MapReduce/Hadoop-Mapreduce-examples-2.6.0.Output Input Jar WordCount
4. Menunjukkan hasil
Mula -mula semak nama fail hasil yang dibuat di bawah [e -mel dilindungi]/hadoop/output sistem fail menggunakan arahan berikut.
$ HDFS DFS -LS/USER/HADOOP/OUTPUT
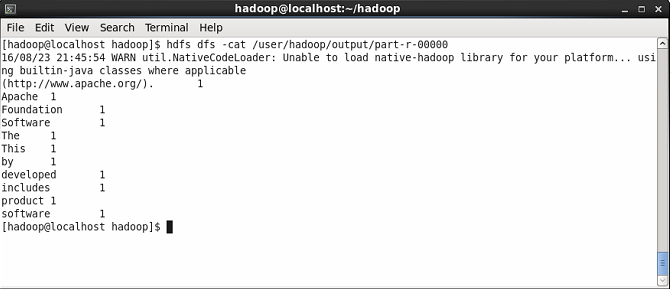
Sekarang tunjukkan kandungan fail hasil di mana anda akan melihat hasil wordcount. Anda akan melihat kiraan setiap perkataan.
$ HDFS DFS -CAT/USER/HADOOP/OUTPUT/Part-R-00000
- « Cara Memasang GO 1.19 di Fedora 36/35 & Centos/RHEL 8/7
- Cara Memasang Apache Maven di CentOS/RHEL 8/7 »